One of the things that statisticians do is statistical inference.
In computer science, statistical inference is called learning.
Inference is the process of using data to infer the distribution that generated the data.
We are usually blessed with only one dataset. We think of it as being drawn from some data generating process.
We want to infer either the entire data generating process or features of the data generating process using only one dataset.
We are actually reversing the process you have been seeing in our discussions of probability and random variables.
There are three major types of inference:
Point estimation, e.g. the sample mean as a way to learn \(\mu\)
Confidence sets, e.g., finite sample confidence intervals using Chebyshev’s inequality
Hypothesis testing, e.g. introduced immediately in the first three weeks of the course
Slightly more specific:
Point estimation: Providing a best guess of some unknown quantity of interest – could be a parameter or an entire function
Confidence sets: Providing a “range” of values which “trap” some unknown quantity of interest with a pre-specified probability
Hypothesis testing: Start with some default theory, called the null hypothesis, and ask if the data provide sufficient evidence to reject the theory. If not, retain the null hypothesis.
What you have so far
The sample mean \(\overline{X}_n\) is used as a point estimator of \(\mu\).
We constructed a finite-sample confidence interval for \(\mu\) using Chebyshev’s inequality.
In the IID Bernoulli case, \(\mu\) is equal to the probability of success. We have tested the null that the probability of success is equal to some pre-specified value.
But these are extremely limited and there are unanswered questions.
Sometimes we may not necessarily be just interested in \(\mu\).
The guarantee provided by Chebyshev’s inequality can be conservative.
Why are hypothesis tests designed the way they are?
What happens when sample sizes are large?
Effects of increasing sample size on the sampling distribution of \(\overline{X}_n\)
Recall the example where \(X\) is a random variable whose distribution is \(\mathbb{P}\left(X=2\right)=1/10\), \(\mathbb{P}\left(X=3\right)=1/10\), \(\mathbb{P}\left(X=5\right)=8/10\).
Obtain \(n\) IID draws from this distribution.
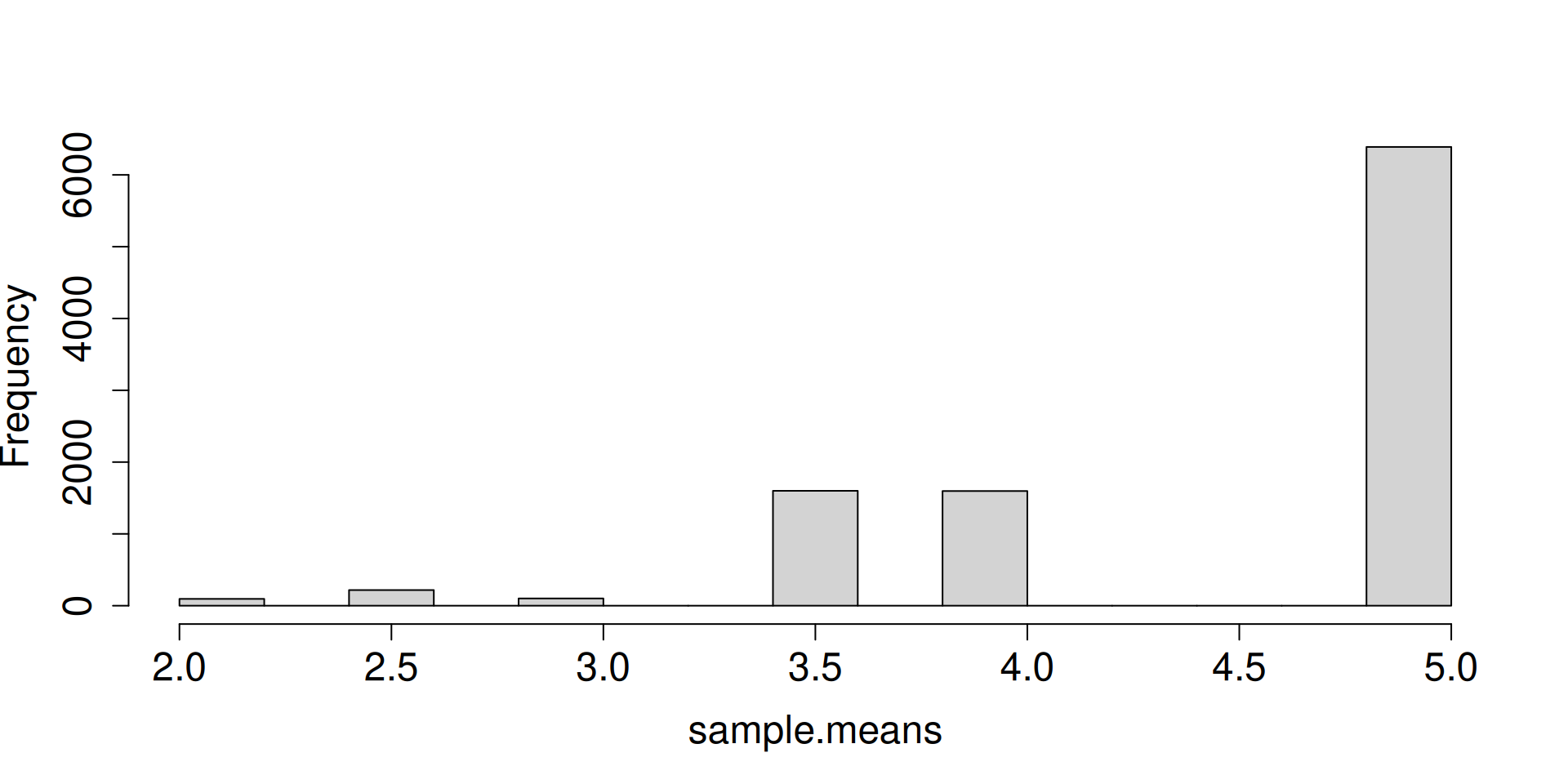
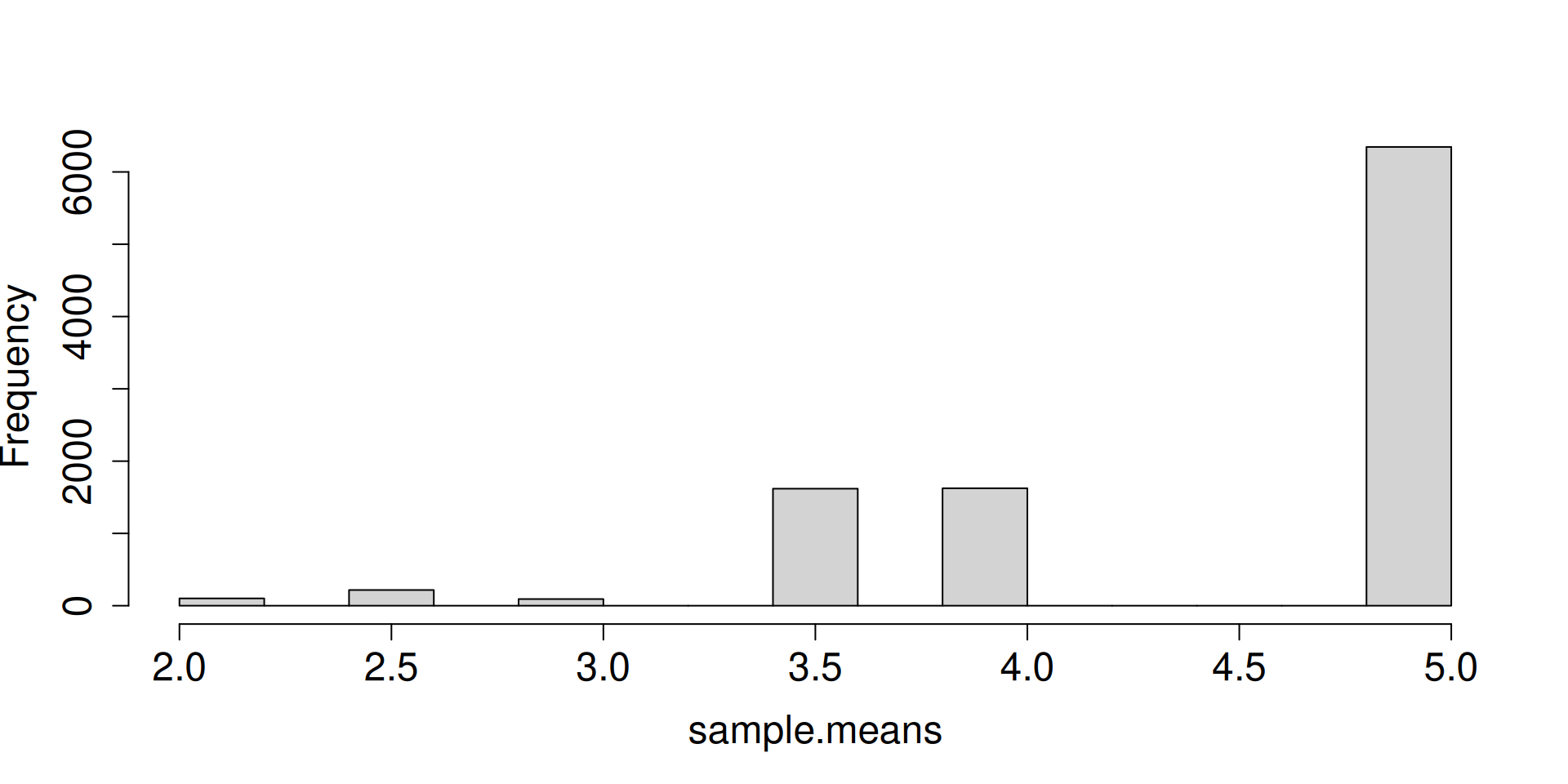
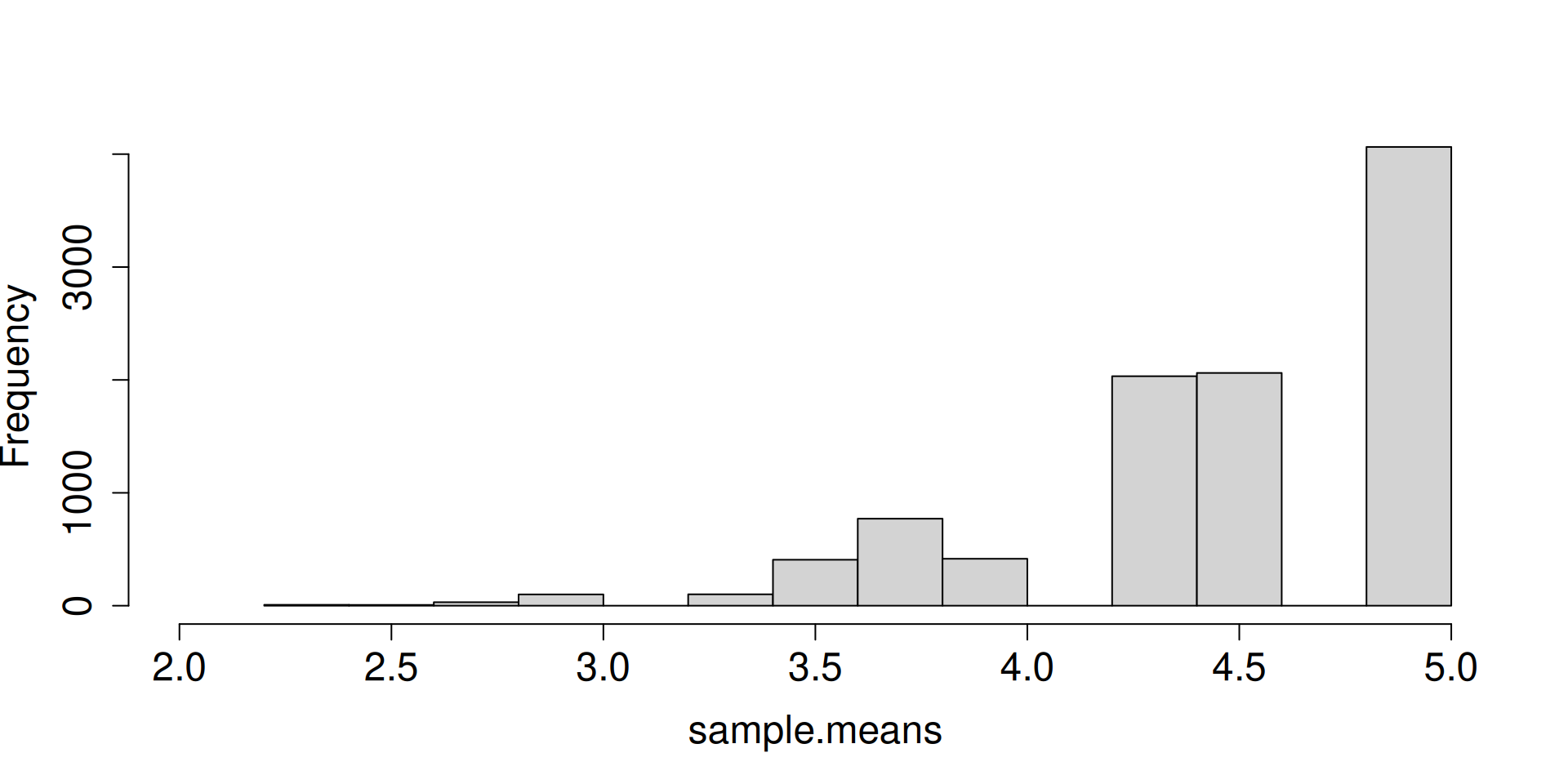
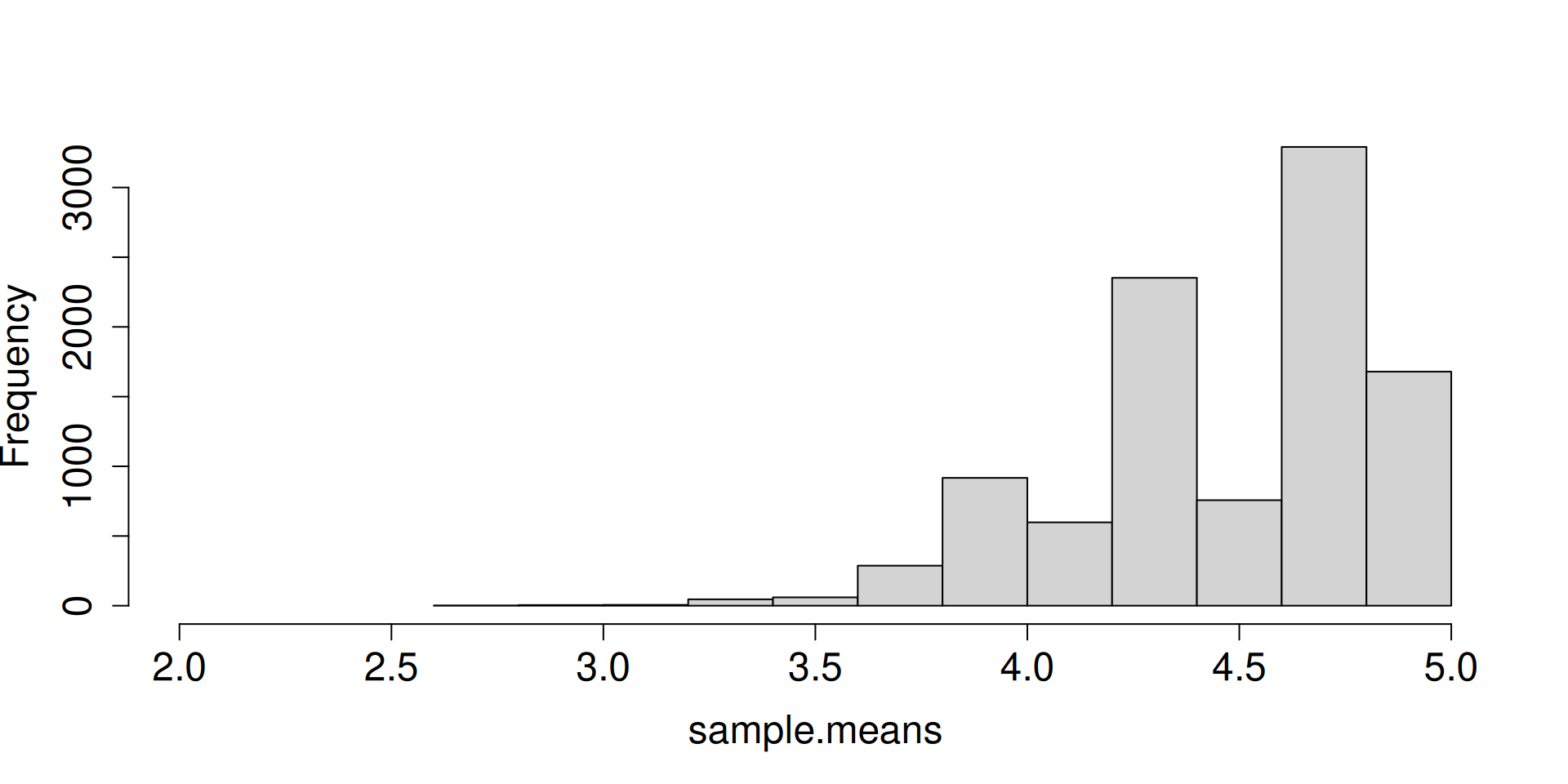
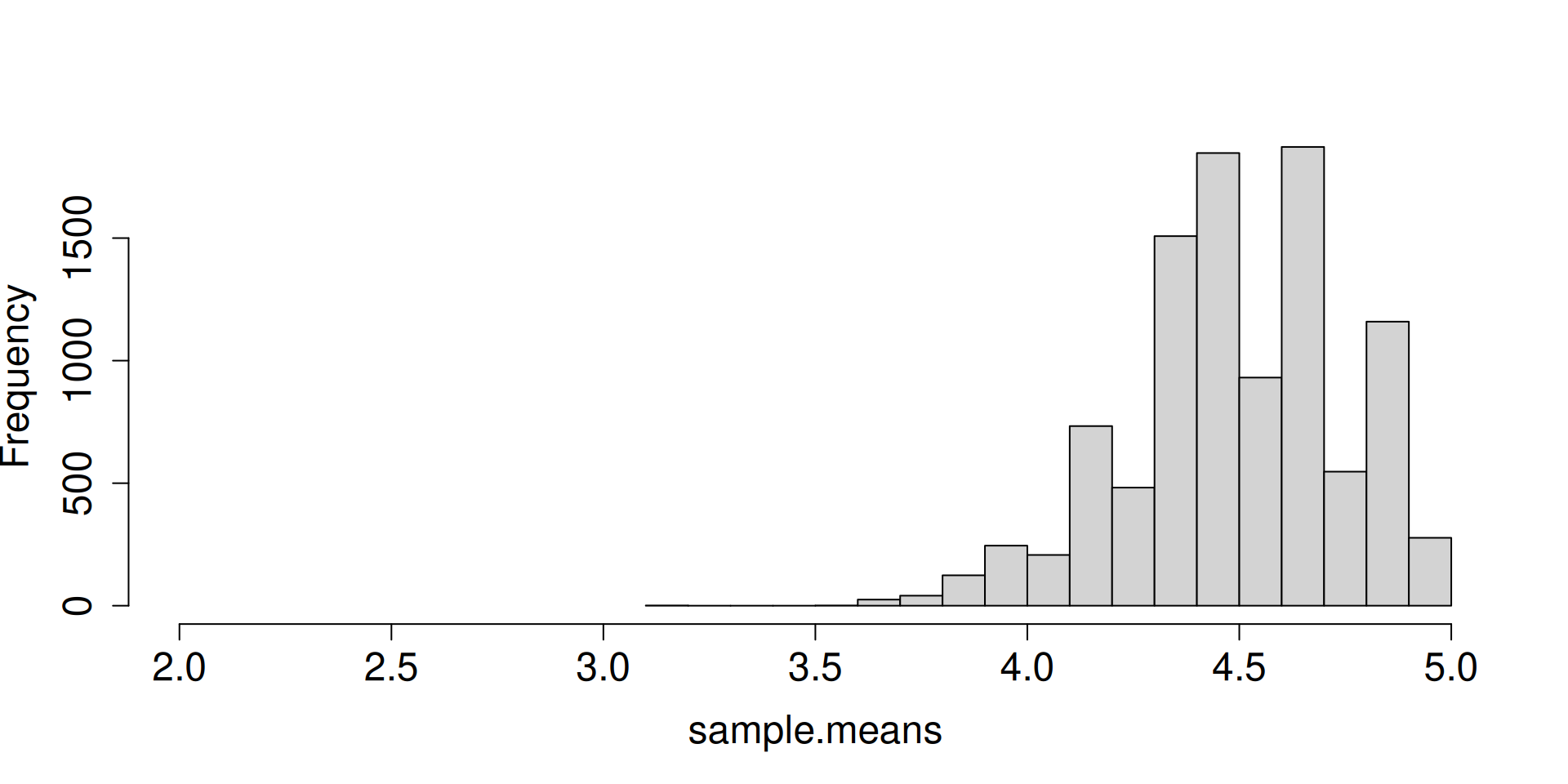
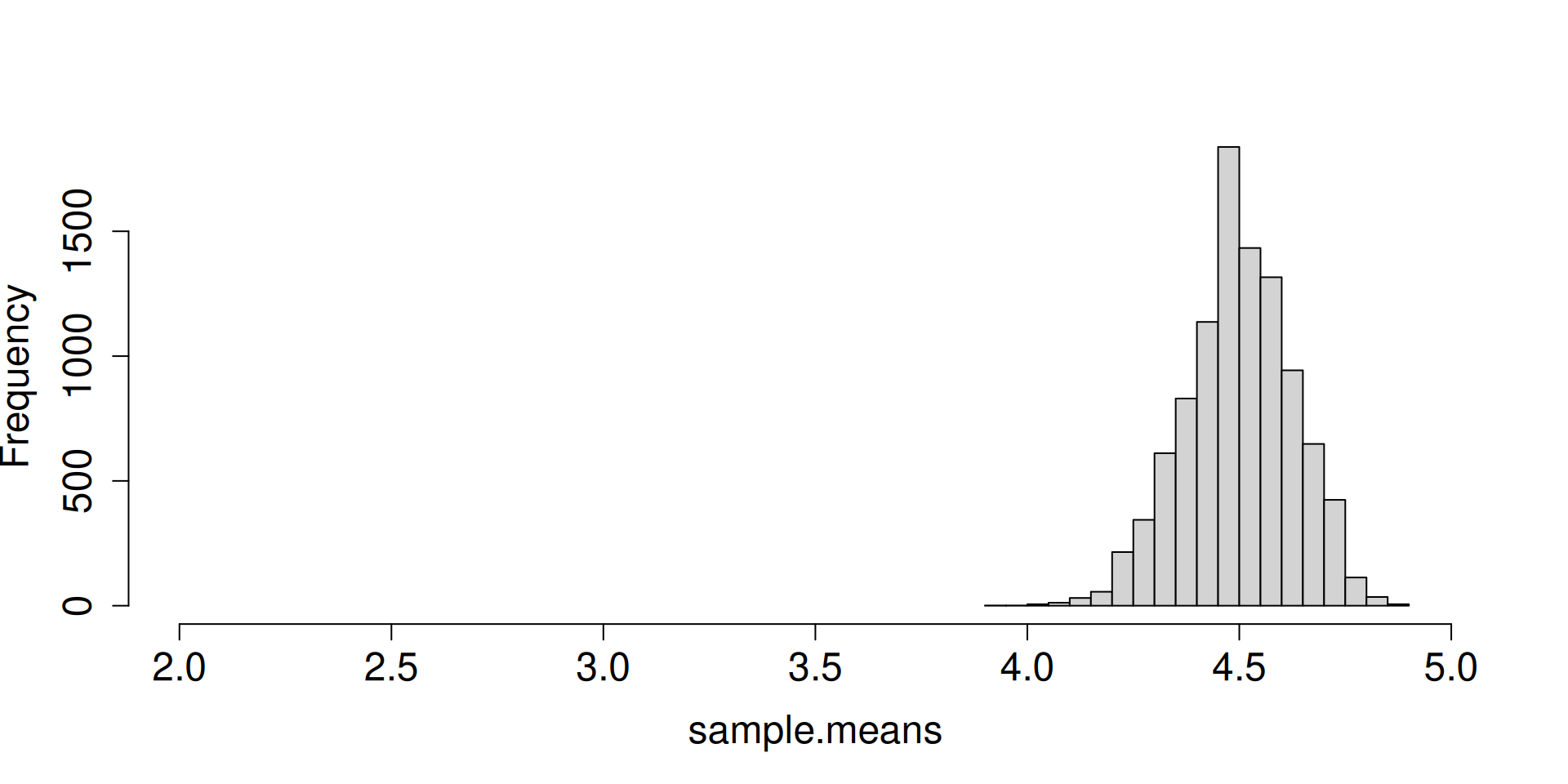
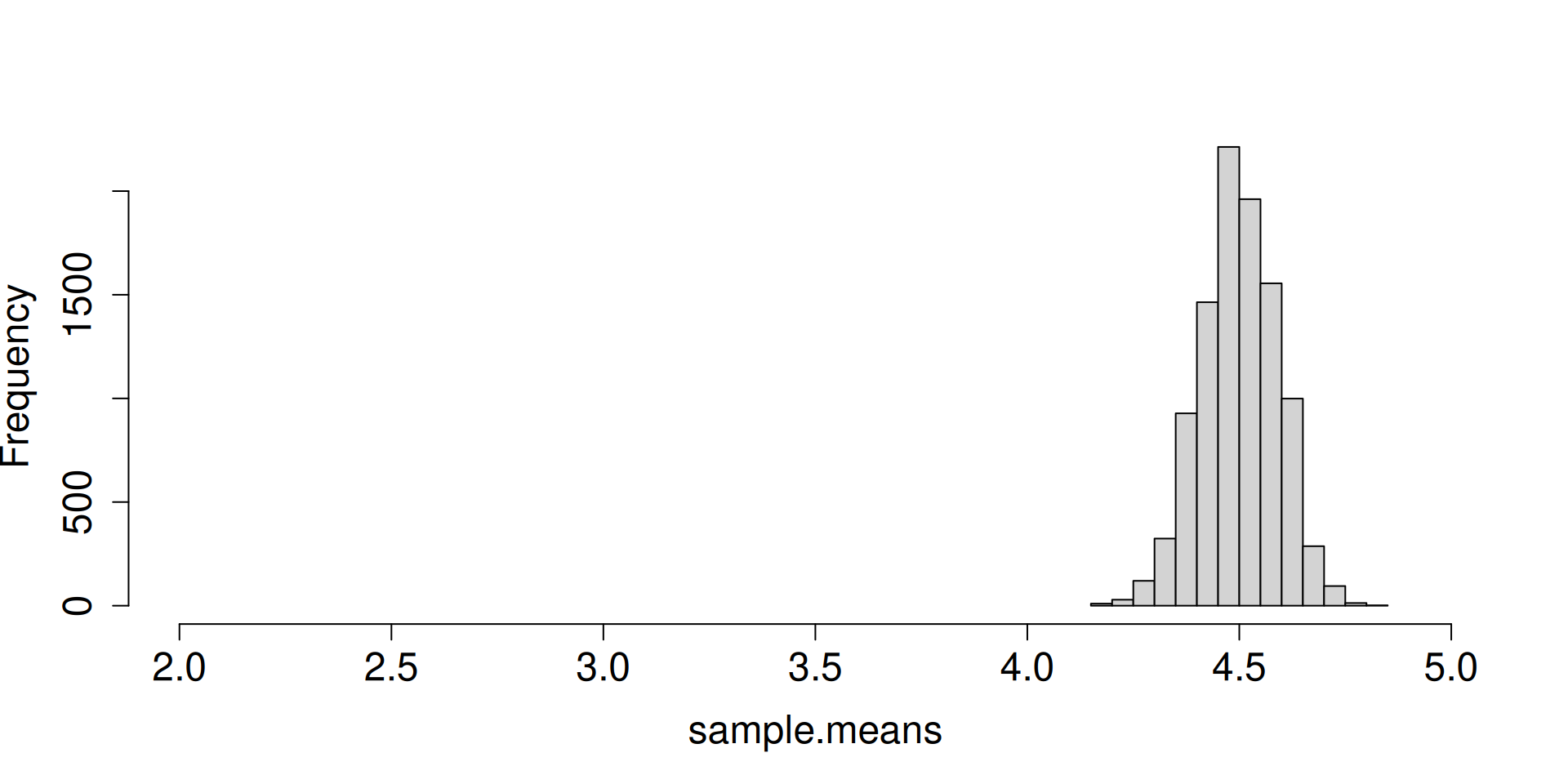
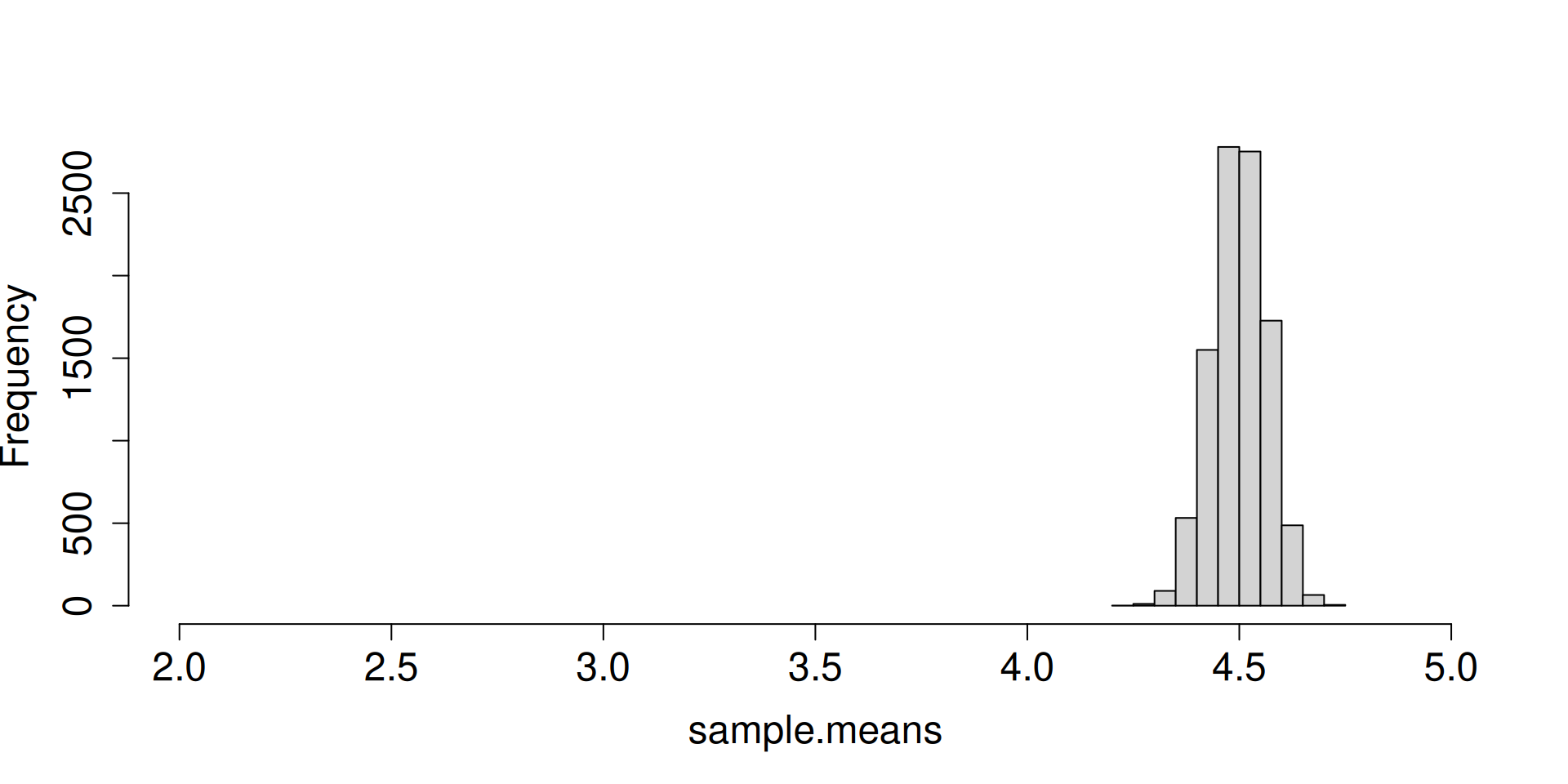
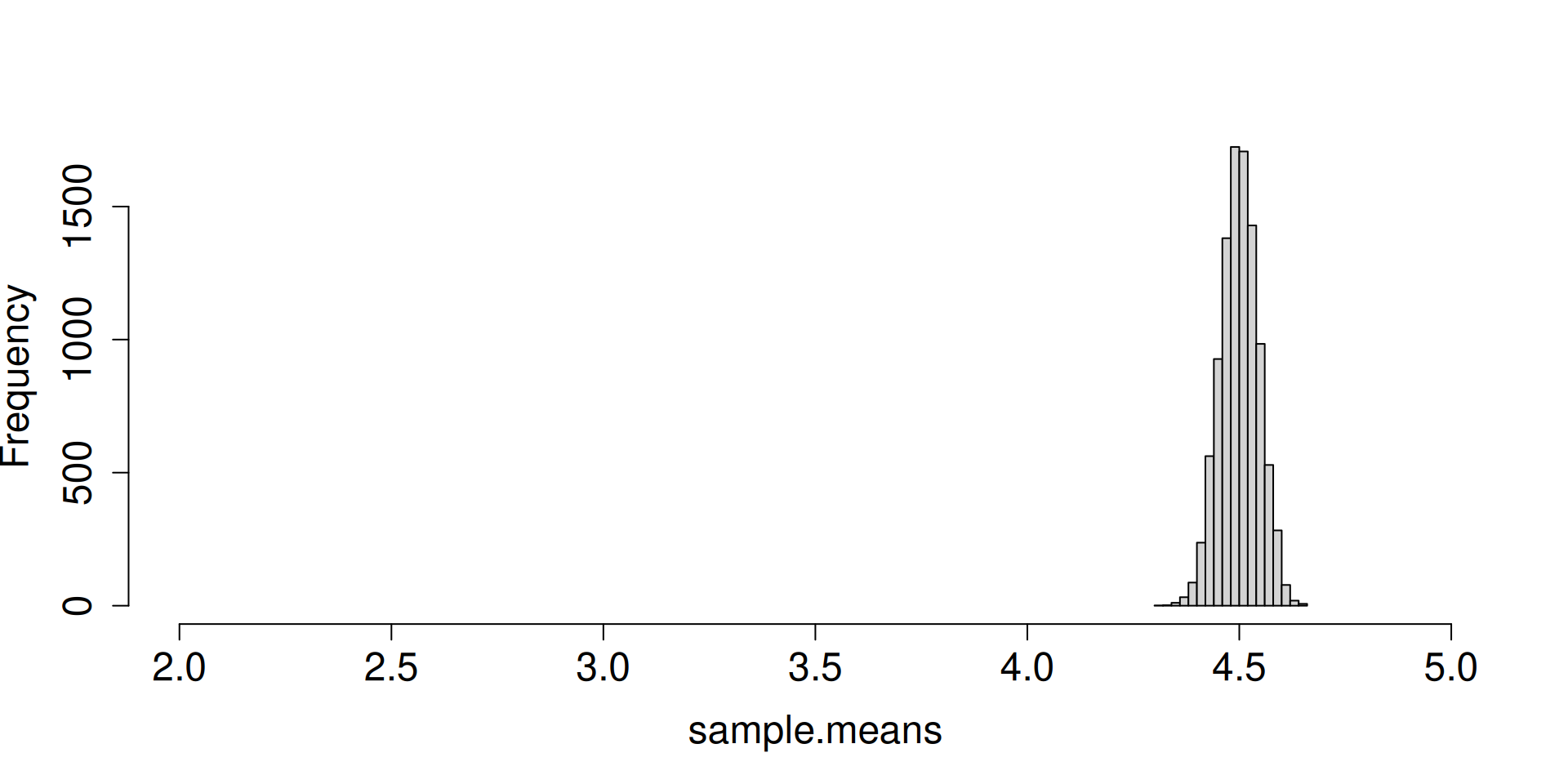
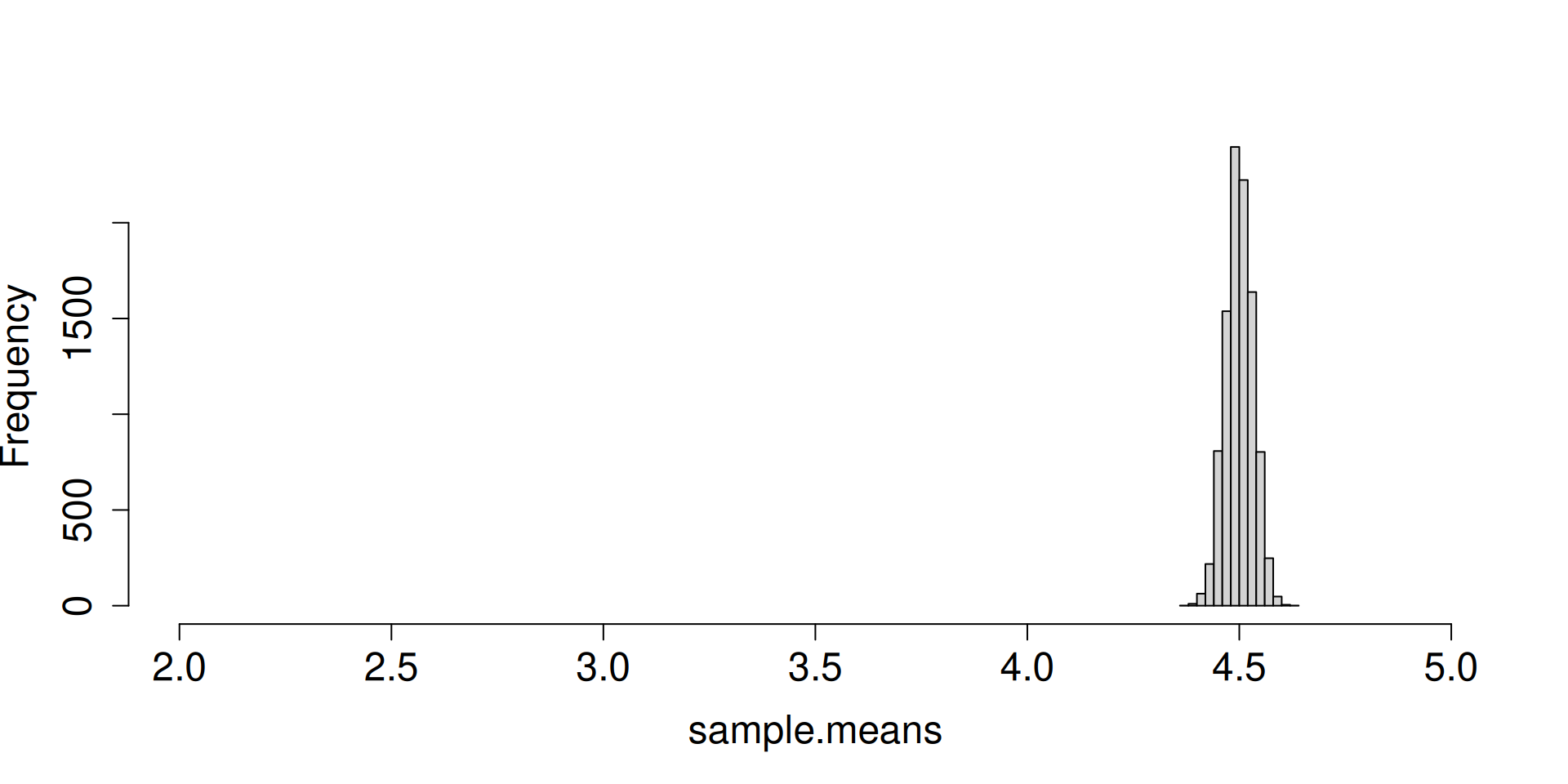
Display the histogram for the sampling distribution of the sample mean.
What do you notice as \(n\to\infty\)?
a <-replicate(10^4, sample(c(2, 3, 5), 2, prob =c(0.1, 0.1, 0.8), replace =TRUE))sample.means <-colMeans(a)hist(sample.means, cex.axis =1.5, cex.lab =1.5, main ="")
a <-replicate(10^4, sample(c(2, 3, 5), 2, prob =c(0.1, 0.1, 0.8), replace =TRUE))sample.means <-colMeans(a)hist(sample.means, cex.axis =1.5, cex.lab =1.5, main ="")
This is really the perfect time to create your own R function (we have seen this many times). You can create histograms, but here I focus on the mean, variance, and standard deviation of the sampling distribution of the sample mean.
dist.mean <-function(n){ a <-replicate(10^4, sample(c(2, 3, 5), n, prob =c(0.1, 0.1, 0.8), replace =TRUE)) sample.means <-colMeans(a)return(c(mean(sample.means), var(sample.means), sd(sample.means)))}
Allow \(n\) to be the input and let it increase in size.
What are the forces at work here? Distribution is getting more and more concentrated at \(\mu\). There seems to be an emerging shape for the distribution as well.
Concentration of the sampling distribution of the sample mean
Theorem 1 (The Weak Law of Large Numbers) If \(X_1, \ldots, X_n\) are IID random variables with mean \(\mathbb{E}(X_i)=\mu\) and \(\mathsf{Var}\left(X_i\right)=\sigma^2\), then for all \(\varepsilon>0\), \[\lim_{n\to\infty} \mathbb{P}\left(|\overline{X}_n-\mu|\geq \varepsilon\right)= 0.\]
You have already seen the law of large numbers at work so many times in the course.
An argument based on Chebyshev’s inequality was also presented in Lecture 5d.
Wasserman (2004, p. 76, Theorem 5.6) actually states the theorem without \(\mathsf{Var}\left(X_i\right)=\sigma^2\), but the proof will no longer be based on Chebyshev’s inequality.
Another way to write the conclusion of the theorem is \[\overline{X}_n\overset{p}{\to} \mu.\]
\(\overline{X}_n\overset{p}{\to} \mu\) is usually expressed in many ways. As \(n\to \infty\),
A law of large numbers applies to \(\overline{X}_n\).
\(\overline{X}_n\) is a consistent estimator of \(\mu\). Refer to Definition 6.7 of Wasserman (2004), p. 90.
The sequence \(\overline{X}_1, \overline{X}_2, \ldots\) converges in probability to \(\mu\).
Take note that \(\mu=\mathbb{E}\left(X_i\right)\), the common mean of the marginal distributions of \(X_1,X_2, ,\ldots\).
The emerging shape of the distribution
Standardize first in order to “counter” two things:
the effect of the distribution “moving” from left to right
the effect of the distribution of the sample mean concentrating at \(\mu\).
Here we know that \(\mathbb{E}\left(\overline{X}_n\right)=\mu\) and \(\mathsf{Var}\left(\overline{X}_n\right)=\sigma^2/n\).
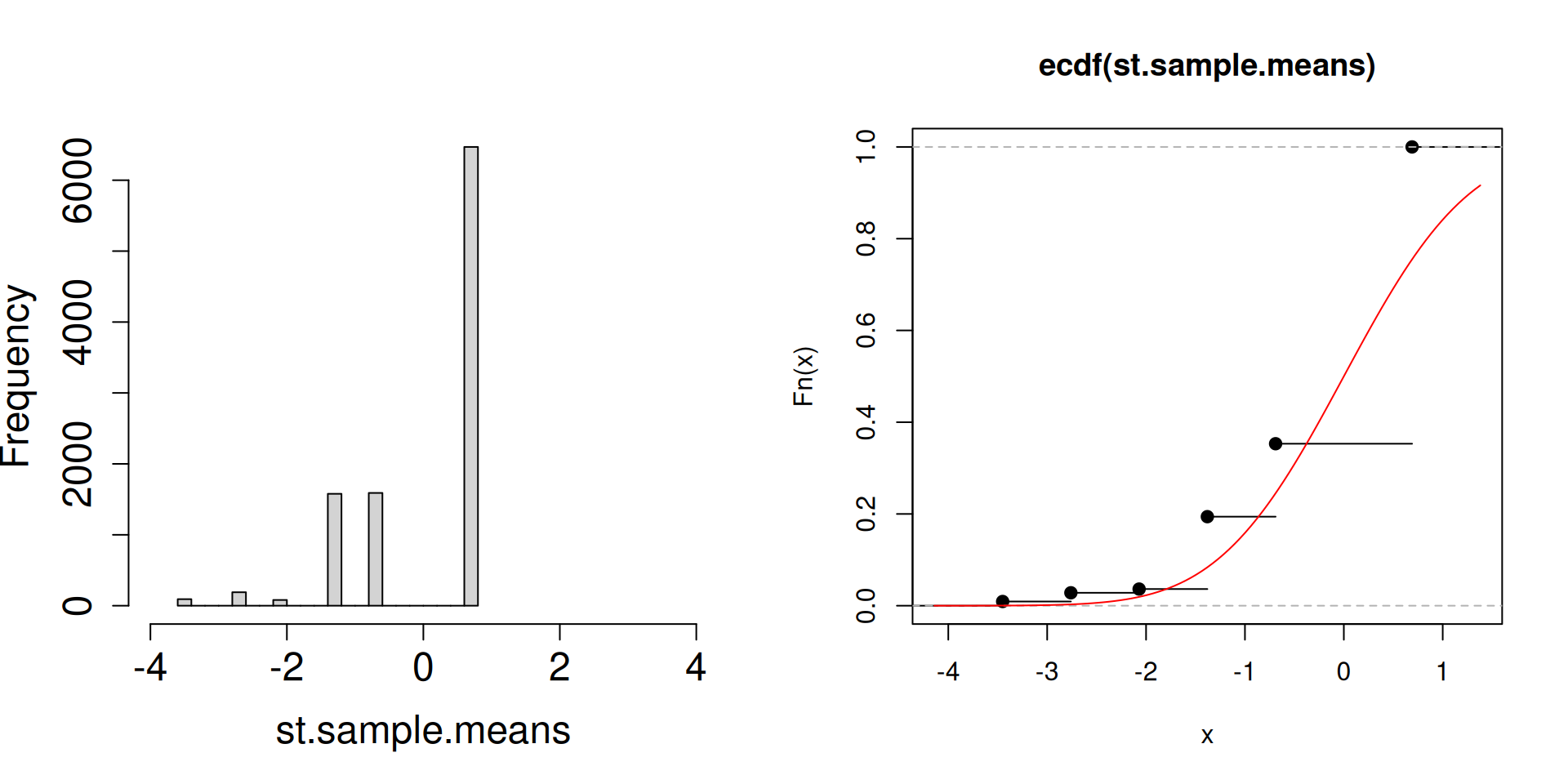
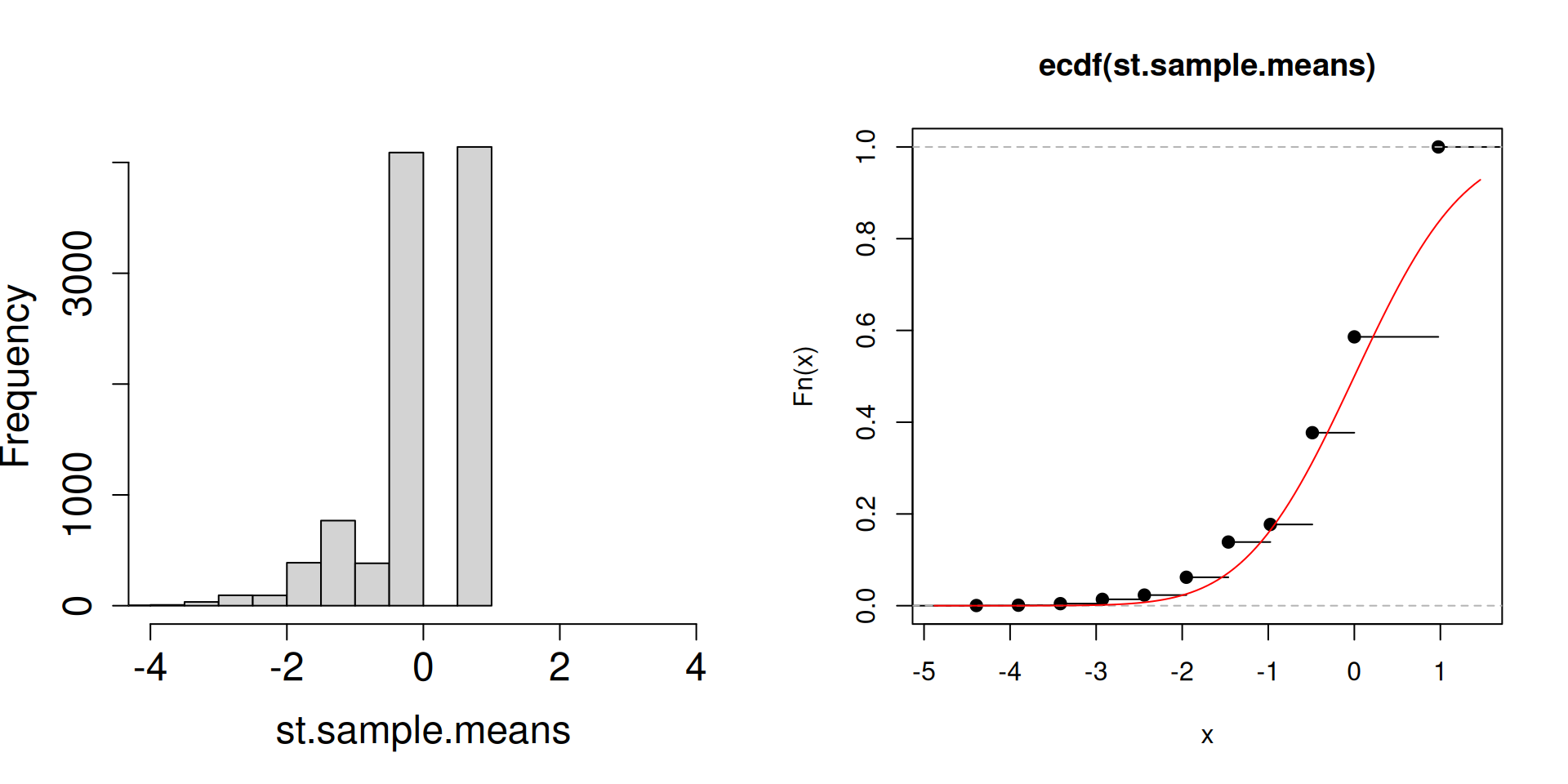
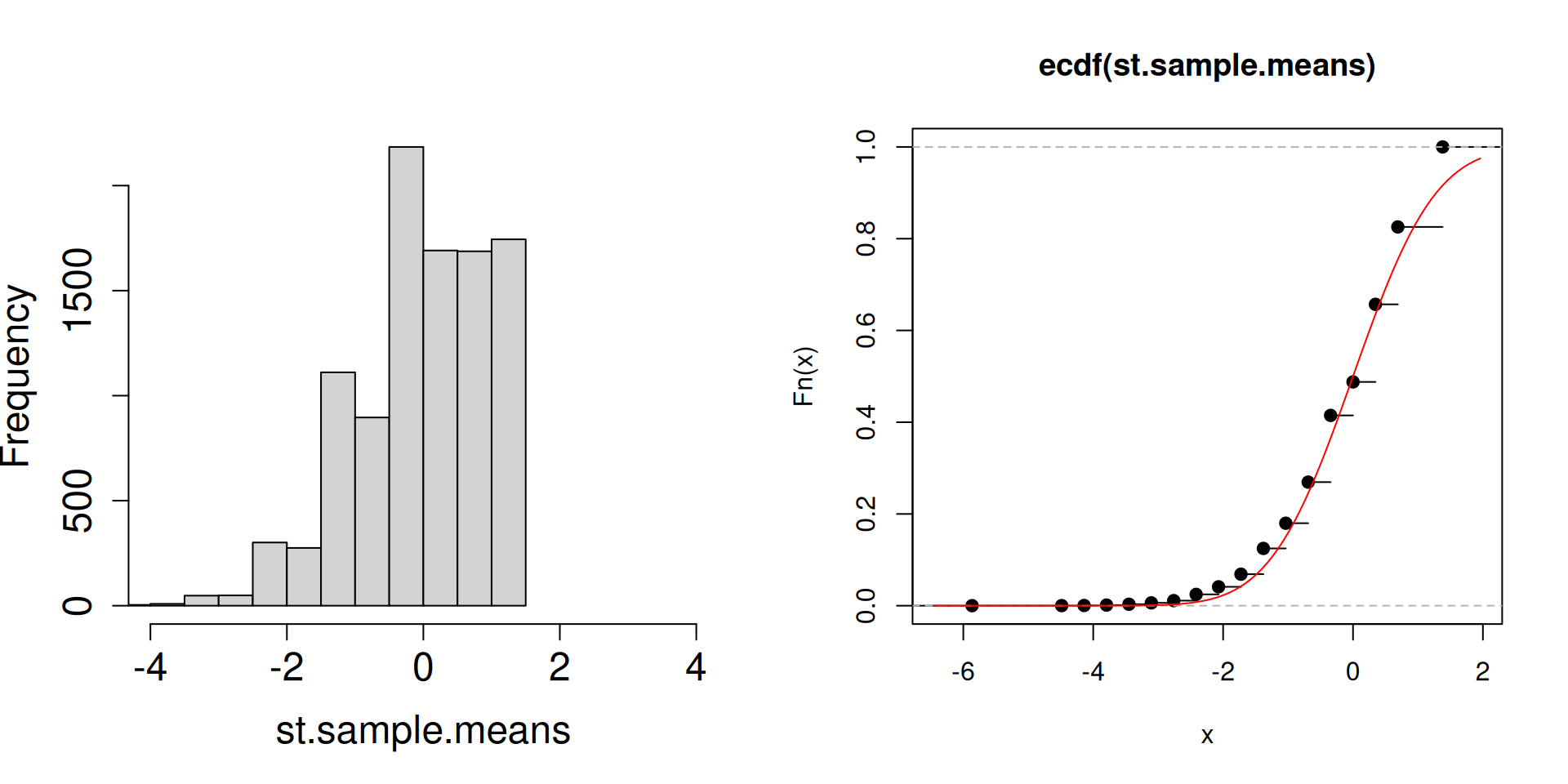
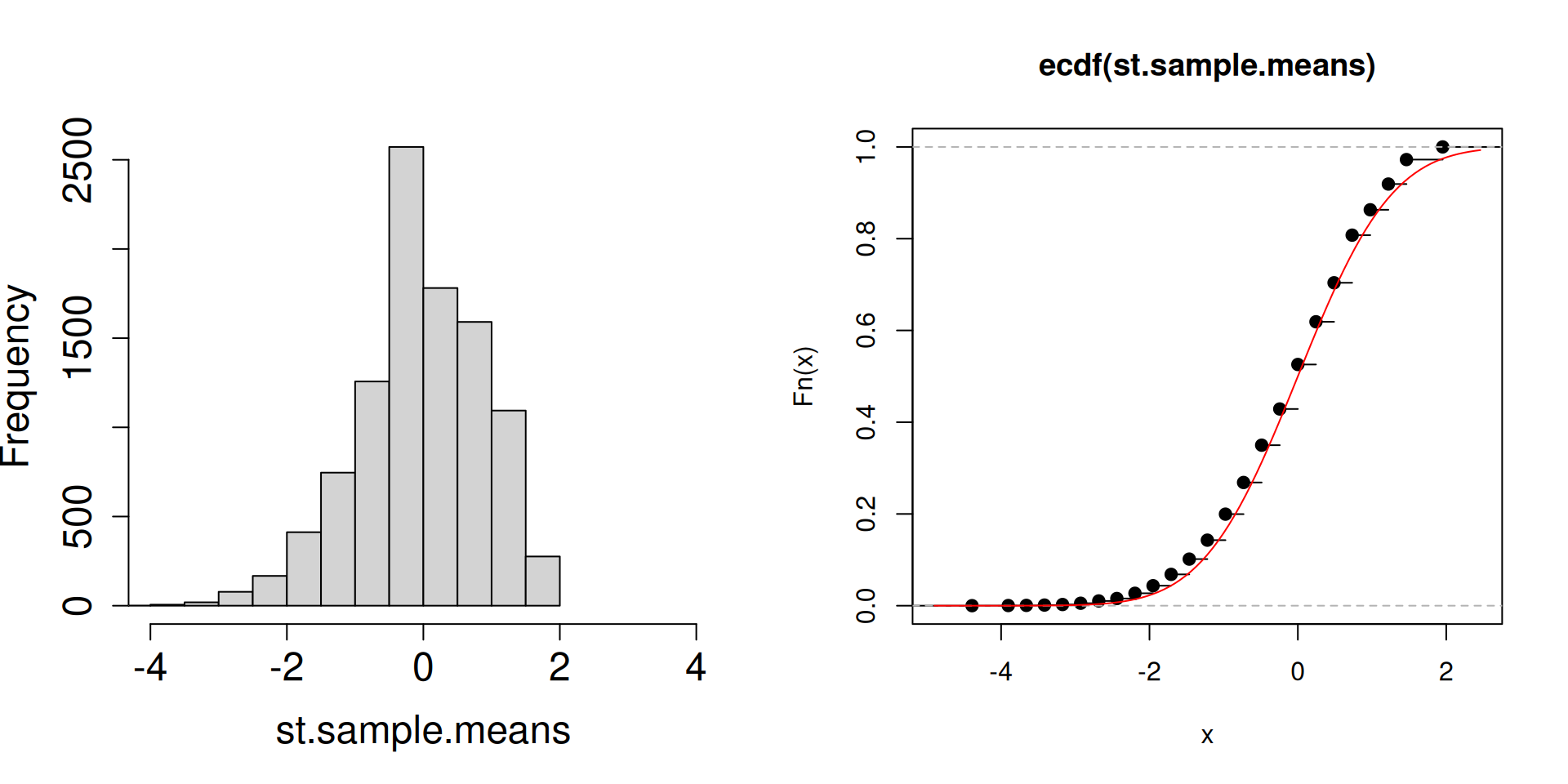
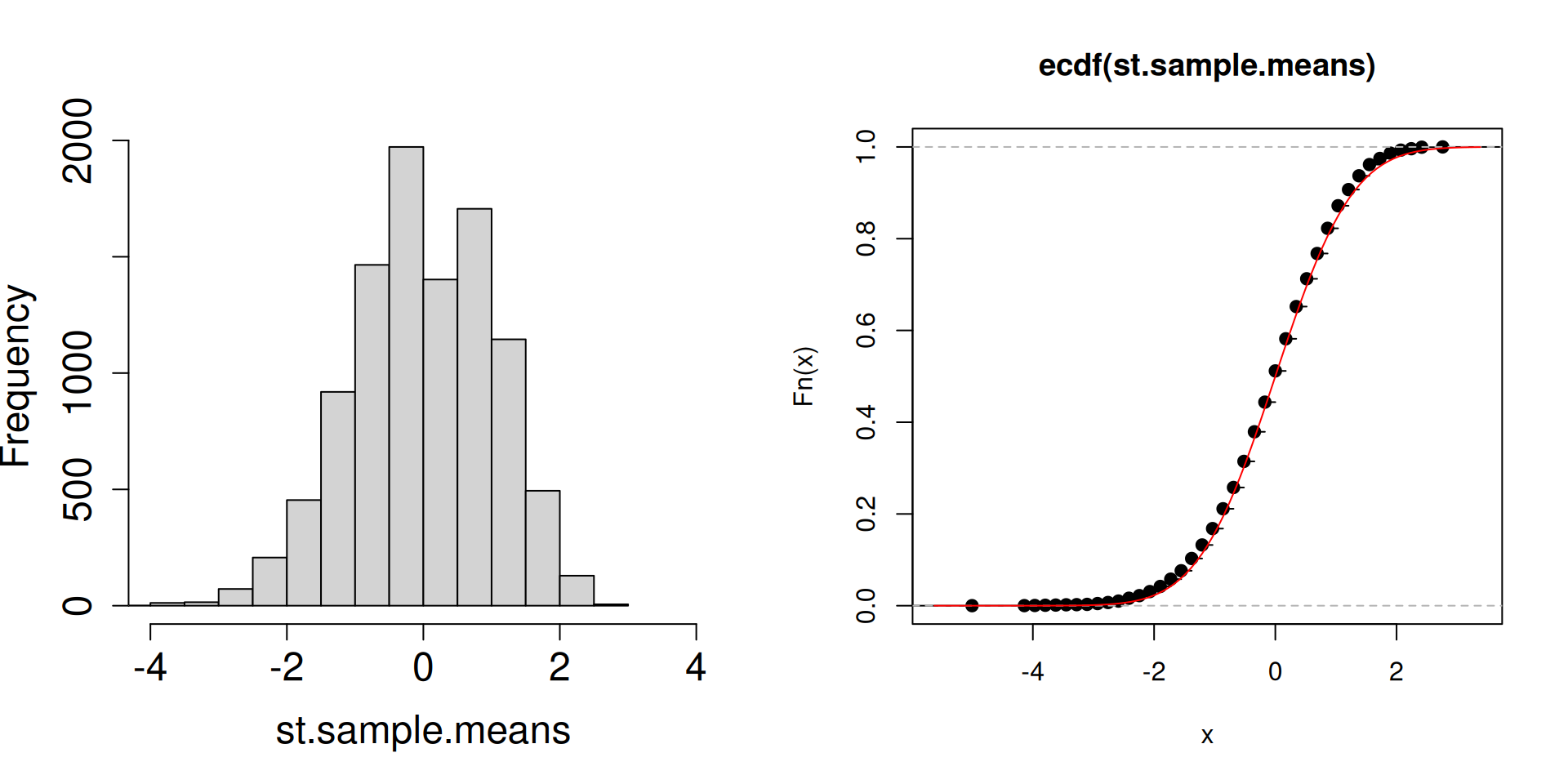
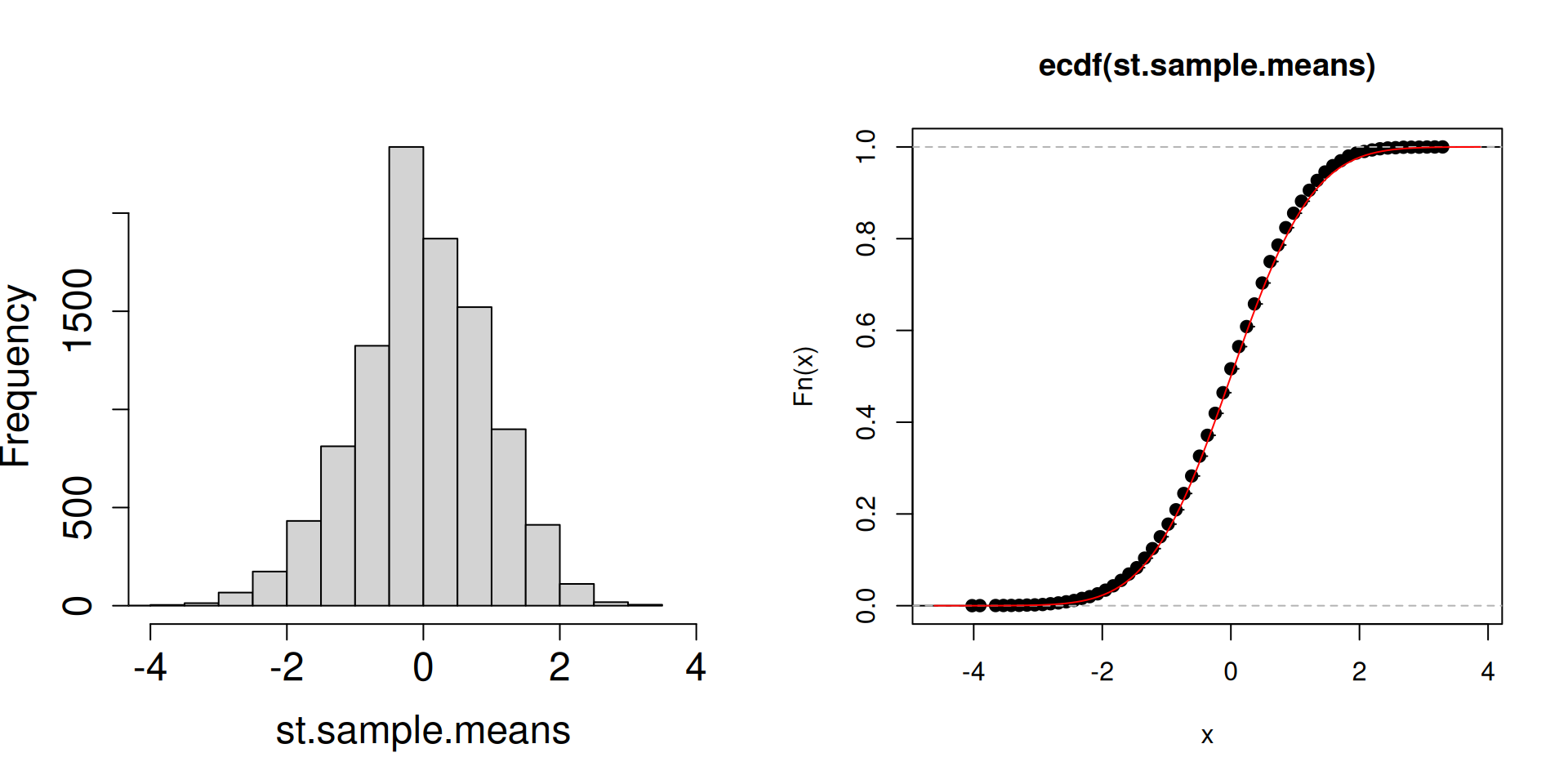
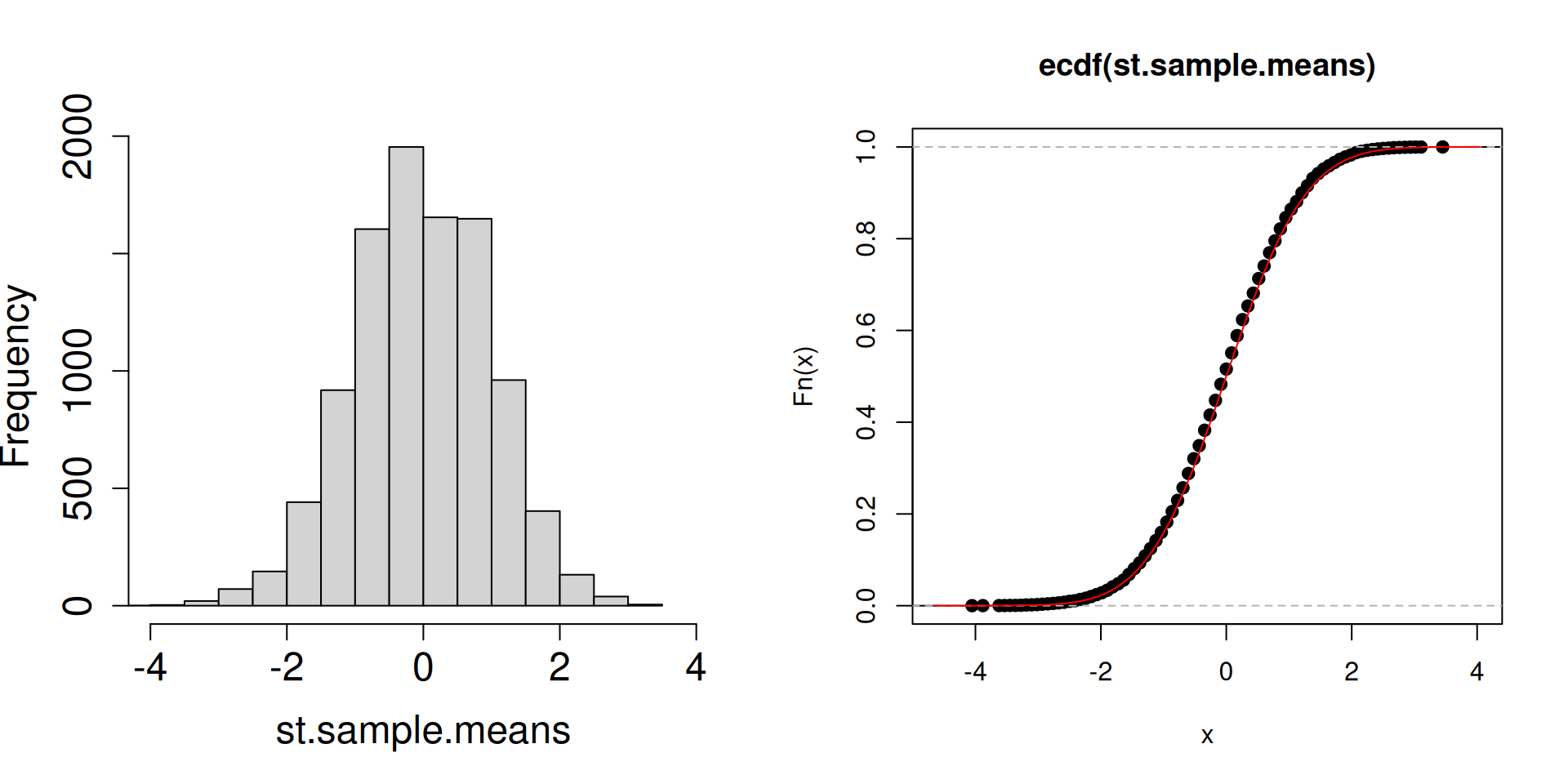
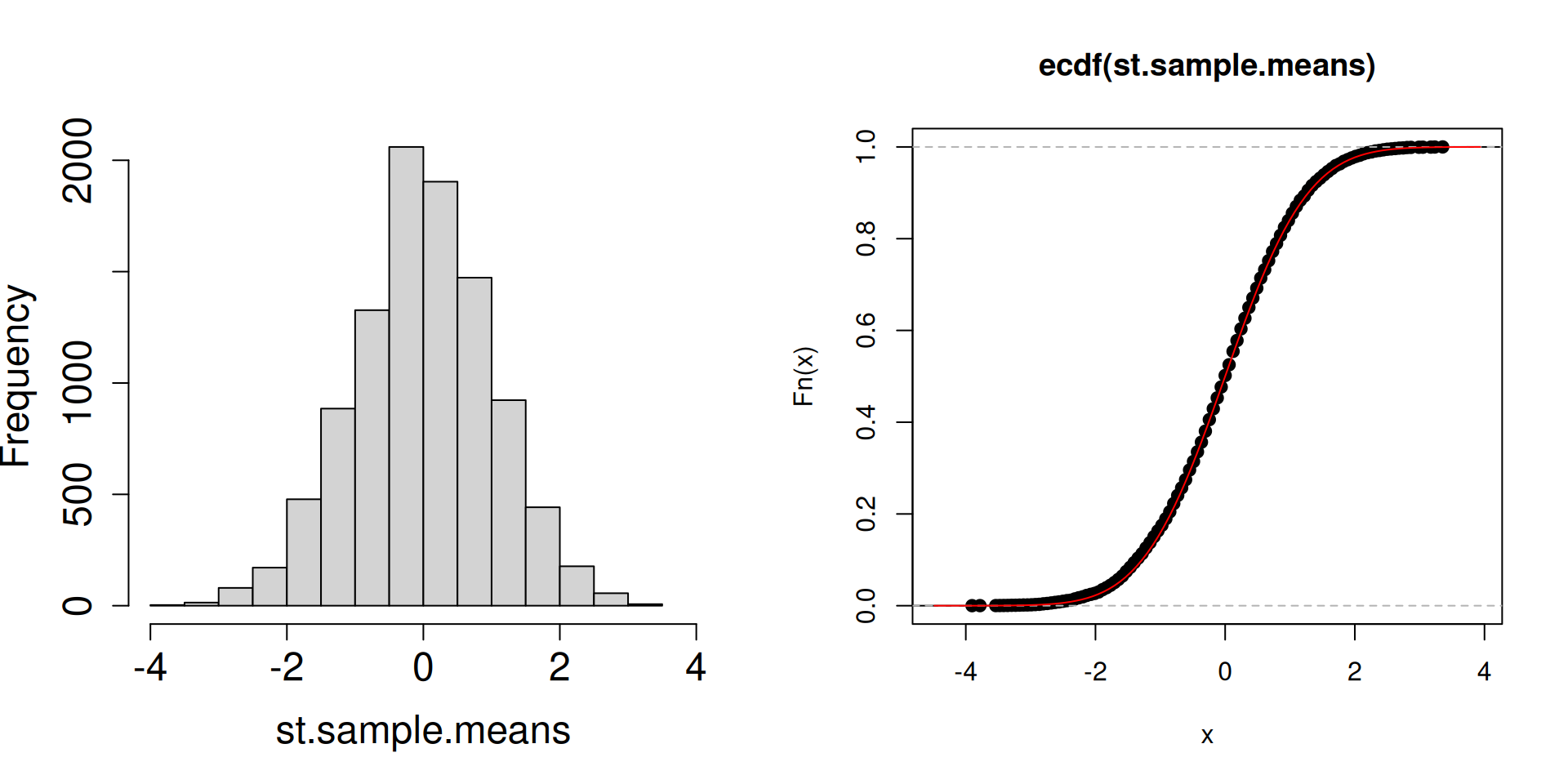
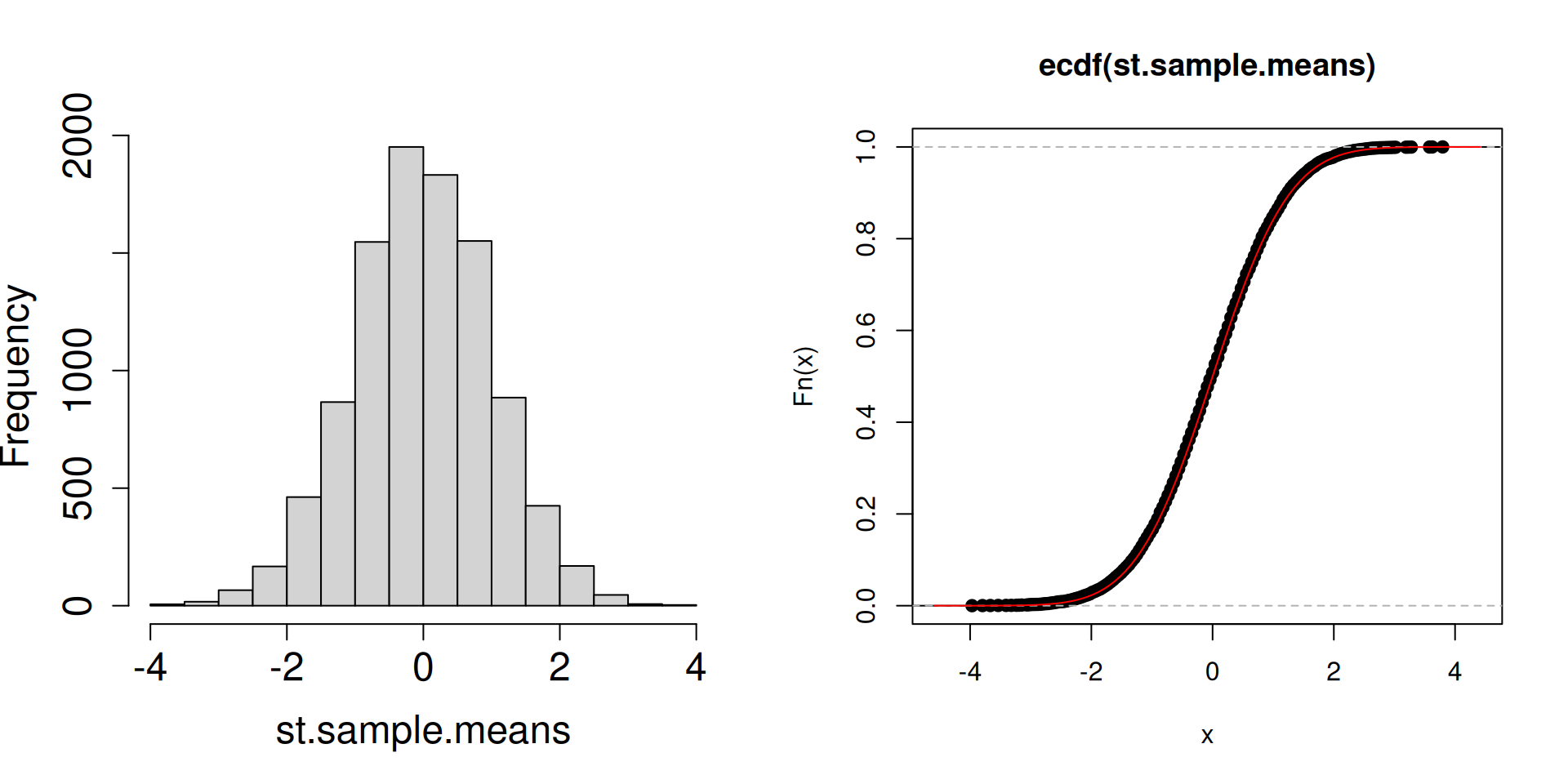
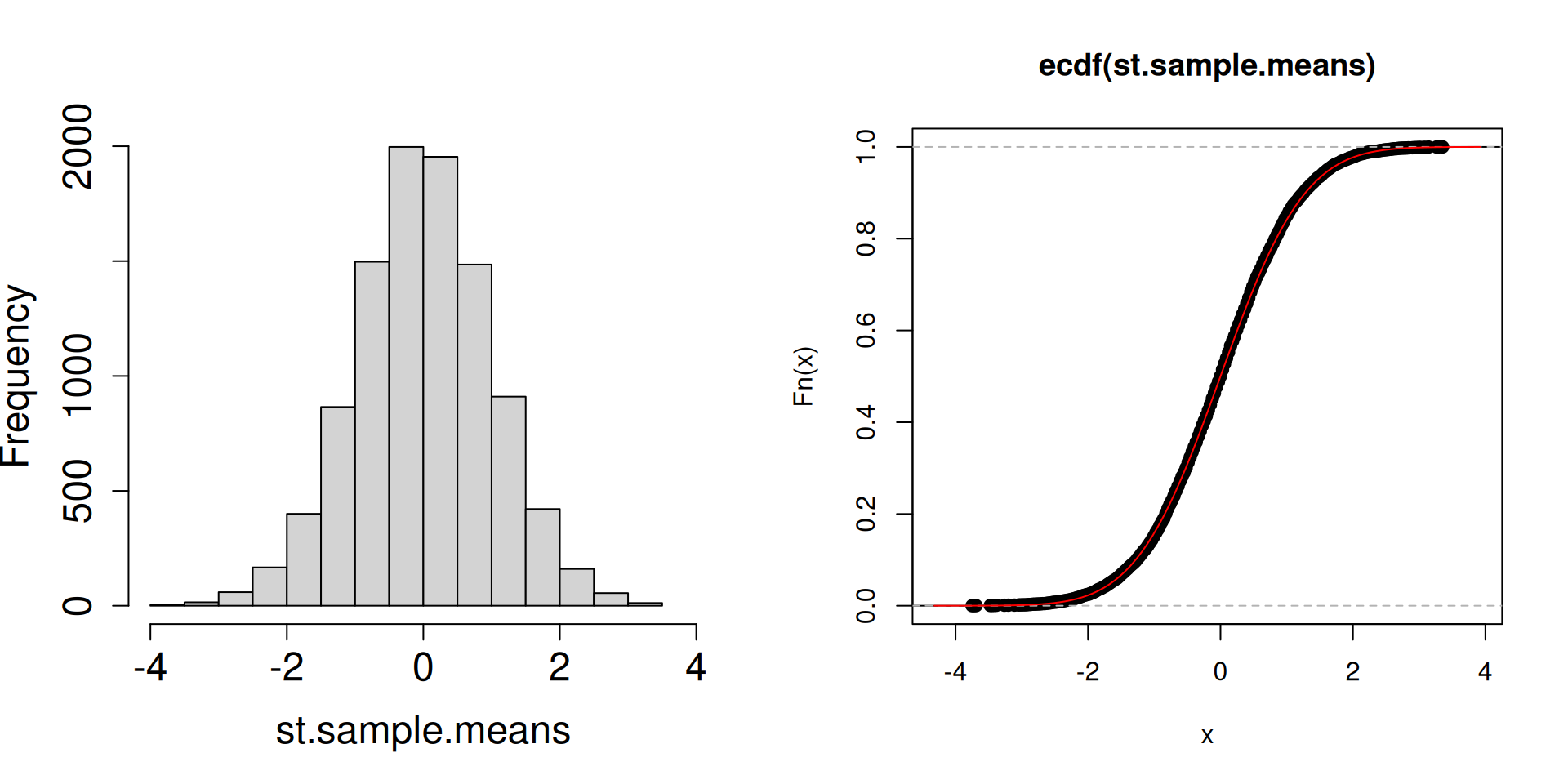
Plot the distribution of the standardized sample mean \(\dfrac{\overline{X}_n-\mu}{\sigma/\sqrt{n}}\) instead.
We know \(\mu\) and \(\sigma^2\) for the purposes of the simulation. In practice, we do not know them (otherwise, what is the point of a statistics course?).
plot.dist.mean <-function(n){ a <-replicate(10^4, sample(c(2, 3, 5), n, prob =c(0.1, 0.1, 0.8), replace =TRUE)) st.sample.means <- (colMeans(a)-4.5)/(sqrt(1.05/n))par(mfrow =c(1, 2))hist(st.sample.means, cex.axis =1.5, cex.lab =1.5, main ="", xlim =c(-4,4))plot(ecdf(st.sample.means))curve(pnorm, add=TRUE, col="red")}
plot.dist.mean(2)
plot.dist.mean(4)
plot.dist.mean(8)
plot.dist.mean(16)
plot.dist.mean(32)
plot.dist.mean(64)
plot.dist.mean(128)
plot.dist.mean(256)
plot.dist.mean(512)
plot.dist.mean(1024)
What is the red curve?
The red curve is actually the cdf of a random variable \(Z\) that has a standard normal distribution (another special distribution). The standard normal cdf is usually written at \(\Phi(z)\) has the following form: \[\Phi(z)=\mathbb{P}\left(Z\leq z\right)=\int_{-\infty}^z \frac{1}{\sqrt{2\pi}}\exp\left(-\frac{1}{2}x^2\right)\, dz.\]
This is probably one of the more famous continuous distributions.
Compared to the cdfs of discrete random variables you have seen so far, the red curve looks very different. In particular, there are no jumps.
What matters is that the cdf of a standard normal random variable is a good approximation of the cdf of the sampling distribution of the standardized sample mean.
We will just take a small dip into continuous random variables.
Digression: Continuous random variables
In the slides, pay attention to whether the word “discrete” was specified or not. Differences compared to discrete random variables:
Probability density functions (pdf) versus probability mass functions (pmf)
Heights of those functions differ in meaning: for the pdf it would be density, for the pmf it would be probability
Heights of a pdf can exceed 1.
Cdf is continuous
No jumps
Quantile function becomes easier to compute
If cdf is differentiable, the derivative of the cdf is the pdf.
In terms of calculations, we have for a continuous random variable \(X\):
Finding the distribution of a transformed random variable becomes harder
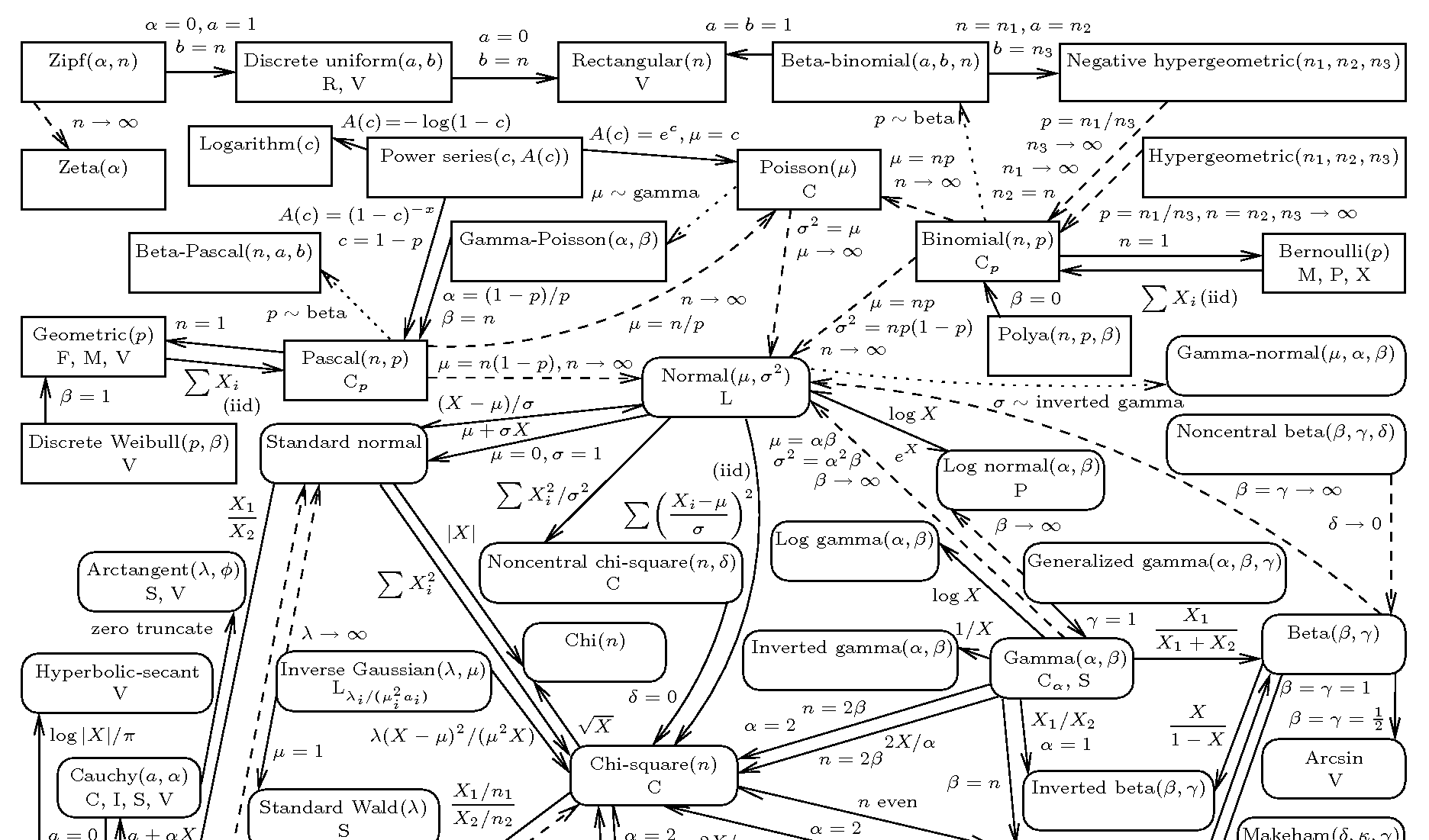
Digression: \(N(0,1)\)
The standard normal distribution has some nice properties:
Its pdf is symmetric about zero. The curve has a peak at 0.
One unit to the left and the right of zero: inflection points, PDF curve changes concavity
The area between -1 to 1 is roughly 68%. The area between -2 to 2 is roughly 95%. The area between -3 to 3 is roughly 99.7%.
Typically, probabilities from the standard normal are obtained from a table or from software.
par(mfrow=c(1,2)) # only for design purposesplot(dnorm, from =-4, to =4)plot(pnorm, from =-4, to =4)
What does the red curve buy us?
We can now calculate probabilities involving the sample mean by directly using a large-sample approximation.
To be more specific, suppose we want to know \(\mathbb{P}\left(\overline{X}_{20} \leq 4.3\right)\) when we have IID random variables \(X_1,\ldots, X_{20}\) from the distribution \(\mathbb{P}\left(X=2\right)=1/10\), \(\mathbb{P}\left(X=3\right)=1/10\), \(\mathbb{P}\left(X=5\right)=8/10\).
This is not really impossible to compute, but it is extremely tedious to construct distribution of \(\overline{X}_{20}\).
In fact, you can find the requested probability directly by simulation.
You can also use Chebyshev’s inequality to give an extremely rough check and it works regardless of the value of \(n\).
Unfortunately, Chebyshev’s inequality gives an upper bound (which may not be very useful).
So having a large-sample approximation might be a good compromise.
Theorem 2 (The Central Limit Theorem (Wasserman (2004) p.77, Theorem 5.8)) Suppose \(X_1, \ldots, X_n\) are IID random variables with mean \(\mathbb{E}(X_i)=\mu\) and \(\mathsf{Var}\left(X_i\right)=\sigma^2\). Then, \[Z_n=\frac{\overline{X}_n-\mathbb{E}\left(\overline{X}_n\right)}{\sqrt{\mathsf{Var}\left(\overline{X}_n\right)}}=\frac{\sqrt{n}\left(\overline{X}_n-\mu\right)}{\sigma}\overset{d}{\to} Z\] where \(Z\sim N(0,1)\). In other words, \[\lim_{n\to\infty}\mathbb{P}\left(Z_n\leq z\right)=\Phi(z).\]
How do we use the theorem so that we can avoid simulation?
Now, based on the central limit theorem: \[\mathbb{P}\left(Z_{30}\leq \frac{4.3-4.5}{\sqrt{1.05/30}}\right) \approx \mathbb{P}\left(Z\leq -1.07\right)\]
pnorm((4.3-4.5)/sqrt(1.05/30))
[1] 0.143
Let us find \(\mathbb{P}\left(\overline{X}_{40} \leq 4.3\right)\) using simulation:
Now, based on the central limit theorem: \[\mathbb{P}\left(Z_{40}\leq \frac{4.3-4.5}{\sqrt{1.05/40}}\right) \approx \mathbb{P}\left(Z\leq -1.23\right)\]
pnorm((4.3-4.5)/sqrt(1.05/40))
[1] 0.109
Let us find \(\mathbb{P}\left(\overline{X}_{50} \leq 4.3\right)\) using simulation:
Now, based on the central limit theorem: \[\mathbb{P}\left(Z_{50}\leq \frac{4.3-4.5}{\sqrt{1.05/50}}\right) \approx \mathbb{P}\left(Z\leq -1.38\right)\]
pnorm((4.3-4.5)/sqrt(1.05/50))
[1] 0.0838
The central limit theorem approximation is getting a bit better.
Note that you have to skeptical of people saying \(n\geq 30\) is a large sample size. It depends on the situation.
You just have to think about how we use 10000 replications in simulation settings to reinforce your skepticism.
Just like Chebyshev’s inequality we do not really need to know fully the common distribution of each of \(X_i\)’s. We only need to know the common mean, common variance, and the sample size.