The building blocks of statistical inference, part 2
Andrew Pua
2024-11-27
Other more important uses of the central limit theorem
Although we used the central limit theorem to make large-sample approximations of probability statements involving the sample mean, this use case can be rather limited.
We do have simulation at our disposal.
But for simulations, we need to know how to generate artificial data obeying the common distribution.
We will return to this issue next time.
The statement \(Z_n\overset{d}{\to} Z\) where \(Z\sim N(0,1)\) is sometimes referred to as
The sequence of standardized sample \(Z_1,Z_2,\ldots\)converges in distribution to \(N(0,1)\).
The standardized sample mean has an asymptotically normal distribution. Refer to Definition 6.12 of Wasserman (2004), p. 92.
We can use the central limit theorem to construct large-sample confidence intervals for \(\mu\).
Why do we need confidence sets?
We want to give a statement regarding a set of plausible values (interval or region) such that we can “cover” or “capture” or “trap” the unknown quantity we want to learn with high probability. Refer to Wasserman (2004) p. 92.
This high probability can be guaranteed under certain conditions. But this is a “long-run” concept applied to the procedure generating the confidence set.
Our target is to construct a large-sample symmetric \(100(1-\alpha)\%\) normal-based confidence set for \(\mu\) if \(\sigma\) is known.
Note that you have to set \(\alpha\) in advance before you implement construct the confidence set.
\(100(1-\alpha)\%\) is called the confidence level.
Symmetry is inherited from asymptotic normality.
The idea is to work backwards from the central limit theorem.
Start from the approximation provided by the central limit theorem, i.e. \[\mathbb{P}\left(-z \leq \frac{\overline{X}_n-\mu}{\sigma/\sqrt{n}} \leq z\right) \approx \mathbb{P}\left(-z\leq Z\leq z\right)\] where \(Z\sim N(0,1)\).
Do some algebra: \[\begin{eqnarray*}&& -z \leq \frac{\overline{X}_n-\mu}{\sigma/\sqrt{n}} \leq z \\ &\Leftrightarrow& \overline{X}_n-z\cdot \frac{\sigma}{\sqrt{n}} \leq \mu \leq \overline{X}_n+z\cdot \frac{\sigma}{\sqrt{n}}\end{eqnarray*}\]
By choosing the appropriate \(z\), you can guarantee that \(\mathbb{P}\left(-z\leq Z\leq z\right)=1-\alpha\). For example, if you want a 95% confidence set for \(\mu\), we need to set \(z=1.96\).
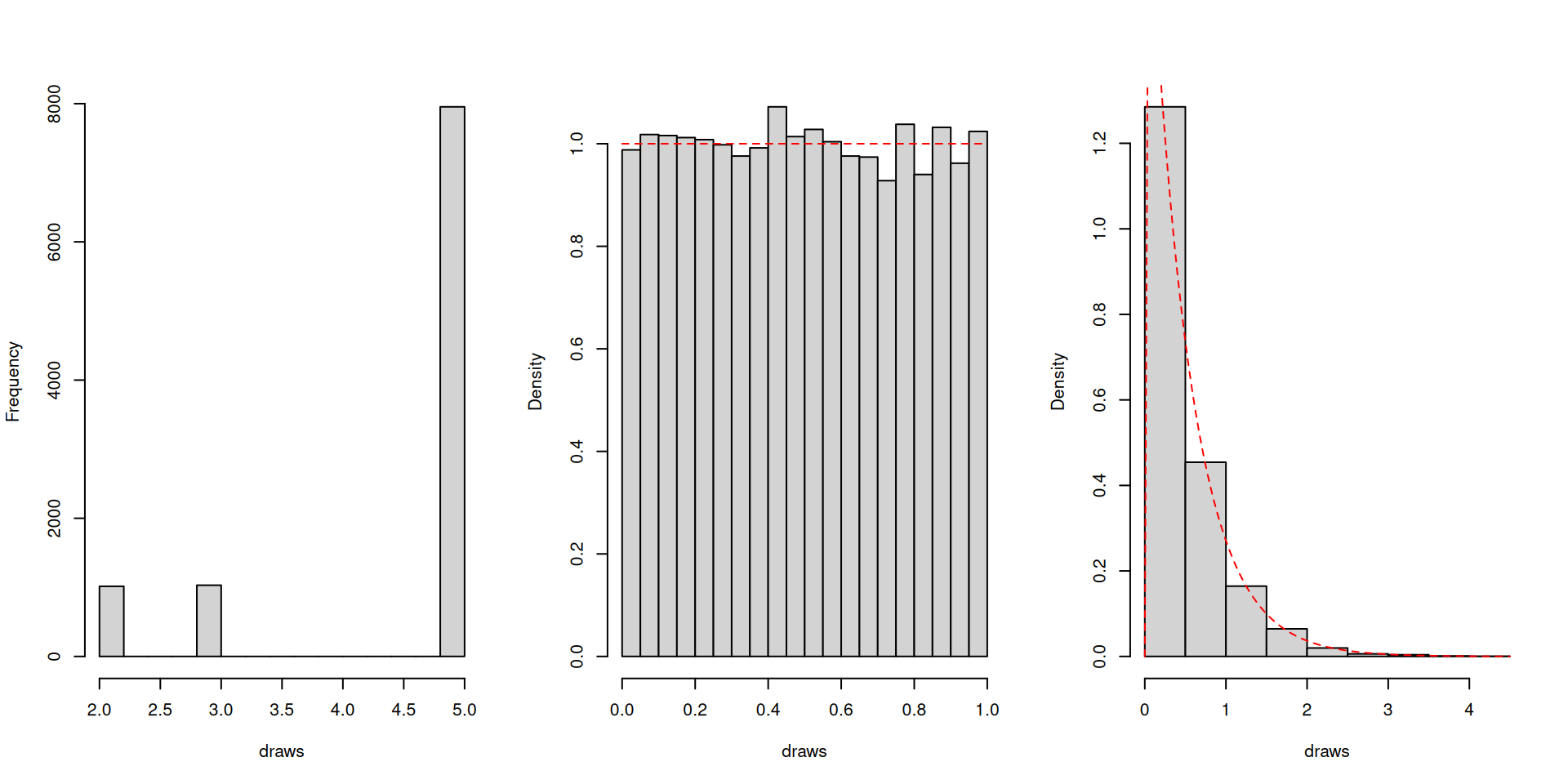
Recall the meaning of confidence level. I will show the performance of a large-sample 95% normal-based confidence interval for \(\mu\) for three distributions:
IID draws from \(\mathbb{P}\left(X=2\right)=1/10\), \(\mathbb{P}\left(X=3\right)=1/10\), \(\mathbb{P}\left(X=5\right)=8/10\): Here \(\mu=4.5\), \(\sigma^2=1.05\).
IID draws from continuous uniform distribution \(U(0,1)\): Here \(\mu=1/2\), \(\sigma^2=1/12\).
IID draws from exponential distribution: Here \(\mu=1/2\), \(\sigma^2=1/4\).
What the distributions look like:
We have the following 95% confidence interval for \(\mu\): \[\overline{X}_n-1.96\cdot \frac{\sigma}{\sqrt{n}} \leq \mu \leq \overline{X}_n+1.96\cdot \frac{\sigma}{\sqrt{n}}.\]
We can check the rate of “capture” because we know everything in the simulation.
Three numbers are reported: the “coverage” or “capture” rate, the rate of “non-capture” on the left, and the rate of “non-capture” on the right
The last two numbers are to determine if symmetry holds up.
For the distribution from Wasserman Chapter 2 Exercise 2:
A cohort of 86 randomly selected students was assigned to the new curriculum.
According to test results that have just been released, those students averaged 502 on their math exam; nationwide, under the old curriculum, students averaged 494 with a standard deviation of 124.
Can it be claimed that the new curriculum made a difference?
What is the parameter of interest?
\(\mu\) as the average math score we could expect the new curriculum to produce if it were instituted for everyone
We are determining whether the evidence from 86 students is compatible with \(\mu=494\) or \(\mu\neq 494\).
The claims \(\mu=494\) and \(\mu \neq 494\) are called the null and alternative hypotheses, respectively. Recall that these claims are about an unknown population quantity.
To determine whether the data has support for the null or the alternative:
The idea is to compute how probable are hypothetical sample means more “extreme” than the observed sample mean would be if we assume that the null is true.
The alternative hypothesis provides the direction of where the “extremes” could be.
One “extreme” direction is anything larger than 502. Besides, a new curriculum is supposed to improve things, right?
In other words, we want to find \[\mathbb{P}_{\mu=494}\left(\overline{X}_{86} > 502\right).\]
But we can’t use simulation directly.
We do not know the distribution to generate artificial data. Compare with Harley’s case.
Use the central limit theorem instead.
Proceeding in the same way as approximating probabilities using the central limit theorem, \[\begin{eqnarray*} && \mathbb{P}_{\mu=494}\left(\overline{X}_{86} > 502\right) \\ &=& \mathbb{P}_{\mu=494}\left(\frac{\overline{X}_{86}-\mu}{\sigma/\sqrt{n}} > \frac{502-\mu}{\sigma/\sqrt{n}}\right) \\ &=&\mathbb{P}_{\mu=494}\left(\frac{\overline{X}_{86}-494}{124/\sqrt{86}} > \frac{502-494}{124/\sqrt{86}}\right) \\
&\approx & \mathbb{P}\left(Z > 0.598 \right)\end{eqnarray*}\]
From standard normal tables or using pnorm() in R, we can find \[\mathbb{P}_{\mu=494}\left(\overline{X}_{86} > 502 \right) \approx 0.2748.\]
pnorm(502, mean =494, sd =124/sqrt(86), lower.tail =FALSE)
We have yet to account for the other direction of “extreme” provided by the alternative hypothesis in our context.
Since the standard normal distribution is symmetric, we can just multiply \(\mathbb{P}_{\mu=494}\left(\overline{X}_{86} > 502 \right)\) by 2 and obtain \(0.55\).
The value \(0.55\) is called a two-sided \(p\)-value, while the value \(0.2748\) is called a one-sided \(p\)-value. A one-sided \(p\)-value of \(0.2748\) suggests that observing sample means equal or greater than 502 (what we actually observe) is about 27% if we assume that the null is true.
Just like before, you have to decide whether a value like 27% will make you find support for the null or the alternative. Some may feel that this is large enough to provide evidence to support the null rather than the alternative.
Had the value been something like 2% (for example), then you may feel that this is small enough to provide evidence against the null.
It is at this stage where conventions of judging what is small or large will definitely arise.
Why are tests designed the way they are?
There are actually two outcomes of a test – either we find evidence in support of the null or we find evidence incompatible with the null.
How do we choose or decide? It all depends on a decision rule, which has to be specified in advance of seeing the data.
Our decision rule would also have two possible outcomes. But regardless of our decision, we do not really know whether the null is true or not.
Therefore, we have four possible outcomes taking into account the truth of the null:
Correctly rejecting the null when the null is false
Correctly retaining the null when the null is true
Incorrectly rejecting the null when the null is true: called a Type I error
Incorrectly retaining the null when the null is false: called a Type II error
Traditionally, Type I errors are considered to be more serious than Type II errors.
This stems from a rather conservative viewpoint with respect to how scientific findings should change the way we see the world.
Type II errors are more difficult to “control”, because there is an extremely wide spectrum of how false a null could be.
Design a decision rule, so that, in the “long-run”, the Type I error rate is guaranteed to be at some pre-specified level.
This pre-specified level is called the significance level, frequently denoted as \(\alpha\).
The word “significance” is used as a technical term and has no relation to our ordinary usage of the term.
Think of the null as a finding that is not statistically different from the status quo. Some call such a finding to be statistically insignificant.
Think of the alternative as a finding that is statistically different from the status quo to warrant attention. Some call such a finding to be statistically significant.
One decision rule is to require that we reject the null whenever the \(p\)-value is less than the significance level \(\alpha\). Otherwise, we fail to reject the null.
Why would this decision rule be a good idea? Let us illustrate with a simulation.
For the simulation, I assume that we have a random sample of \(n\) observations from the three distributions we encountered before.
IID draws from \(\mathbb{P}\left(X=2\right)=1/10\), \(\mathbb{P}\left(X=3\right)=1/10\), \(\mathbb{P}\left(X=5\right)=8/10\): Here \(\mu=4.5\), \(\sigma^2=1.05\).
IID draws from continuous uniform distribution \(U(0,1)\): Here \(\mu=1/2\), \(\sigma^2=1/12\).
IID draws from exponential distribution: Here \(\mu=1/2\), \(\sigma^2=1/4\).
Corresponding to each distribution mentioned in the previous slide, we test the null that
\(\mu=4.5\) against the alternative that \(\mu>4.5\)
\(\mu=1/2\) against the alternative that \(\mu>1/2\)
\(\mu=1/2\) against the alternative that \(\mu>1/2\)
Thus, we have a one-tailed test with \(\alpha=0.05\).
test <-function(n){ data <-sample(c(2, 3, 5), n, prob =c(0.1, 0.1, 0.8), replace =TRUE) test.stat <- (mean(data) -4.5)/(sqrt(1.05)/sqrt(n))return(pnorm(test.stat, lower.tail =FALSE) <0.05)}results <-replicate(10^4, sapply(c(5, 80, 1280), test))apply(results, 1, mean)
[1] 0.0000 0.0407 0.0475
# Effect on not knowing sigmatest <-function(n){ data <-sample(c(2, 3, 5), n, prob =c(0.1, 0.1, 0.8), replace =TRUE) test.stat <- (mean(data) -4.5)/(sd(data)/sqrt(n))return(pnorm(test.stat, lower.tail =FALSE) <0.05)}results <-replicate(10^4, sapply(c(5, 80, 1280), test))apply(results, 1, mean)
[1] 0.3230 0.0768 0.0547
test <-function(n){ data <-runif(n) test.stat <- (mean(data) -1/2)/(sqrt(1/12)/sqrt(n))return(pnorm(test.stat, lower.tail =FALSE) <0.05)}results <-replicate(10^4, sapply(c(5, 80, 1280), test))apply(results, 1, mean)
[1] 0.0483 0.0501 0.0513
# Effect on not knowing sigmatest <-function(n){ data <-runif(n) test.stat <- (mean(data) -1/2)/(sd(data)/sqrt(n))return(pnorm(test.stat, lower.tail =FALSE) <0.05)}results <-replicate(10^4, sapply(c(5, 80, 1280), test))apply(results, 1, mean)
[1] 0.0897 0.0535 0.0544
test <-function(n){ data <-rexp(n, rate =2) test.stat <- (mean(data) -1/2)/(sqrt(1/4)/sqrt(n))return(pnorm(test.stat, lower.tail =FALSE) <0.05)}results <-replicate(10^4, sapply(c(5, 80, 1280), test))apply(results, 1, mean)
[1] 0.0648 0.0542 0.0512
# Effect on not knowing sigmatest <-function(n){ data <-rexp(n, rate =2) test.stat <- (mean(data) -1/2)/(sd(data)/sqrt(n))return(pnorm(test.stat, lower.tail =FALSE) <0.05)}results <-replicate(10^4, sapply(c(5, 80, 1280), test))apply(results, 1, mean)
[1] 0.0280 0.0312 0.0426
Can we simultaneously reduce Type I and Type II errors?
Recall that a Type I error is essentially a false positive and a Type II error is essentially a false negative.
You could reduce Type I error by making \(\alpha\) smaller, holding everything else constant.
But if you do this, it becomes harder and harder to reject the null whether or not the null is true. Therefore, the probability of a Type II error will increase.
In a sense, there is a tradeoff when sample sizes are held fixed.
We can try revisiting our simulation earlier and get a sense of the Type II error.
We have to test a false null. But this is complicated given our setup.
For example, when you try altering \(\mu=4.5\) to make it a false null, you may want to think about what kind of distribution would correspond to that particular false null.
It can be difficult to hold everything else constant and only allow \(\mu\) to depart from 4.5.
So, we are trying something different. We are going to draw artificial data from a normal distribution with parameters \(\mu\) and \(\sigma^2\) instead.
This distribution has the characteristic that if \(X\sim N(\mu,\sigma^2)\), then \(\mathbb{E}(X)=\mu\) and \(\mathsf{Var}(X)=\sigma^2\).
You already encountered the standard normal \(N(0,1)\).
This time we generate IID draws from \(N(5,2^2)\). So that we know that \(\mu=5\) is a true null. We test this null against the alternative \(\mu>5\).
test <-function(n){ data <-rnorm(n, mean =5, sd =2) test.stat <- (mean(data) -5)/(sqrt(4)/sqrt(n))return(pnorm(test.stat, lower.tail =FALSE) <0.05)}results <-replicate(10^4, sapply(c(5, 80, 1280), test))apply(results, 1, mean)
[1] 0.0477 0.0514 0.0493
# Effect on not knowing sigmatest <-function(n){ data <-rnorm(n, mean =5, sd =2) test.stat <- (mean(data) -5)/(sd(data)/sqrt(n))return(pnorm(test.stat, lower.tail =FALSE) <0.05)}results <-replicate(10^4, sapply(c(5, 80, 1280), test))apply(results, 1, mean)
[1] 0.0869 0.0504 0.0487
So, the test is performing as good as it could, especially with large samples and when we estimate \(\sigma\).
Let us try a false null, say \(\mu=4.9\), holding everything else constant, against the alternative that \(\mu>4.9\).
Afterwards, we will try testing the false null \(\mu=4.8\), holding everything else constant, , against the alternative that \(\mu>4.8\).
As you can see there is wide spectrum for which we can look at false nulls.
test <-function(n){ data <-rnorm(n, mean =5, sd =2) test.stat <- (mean(data) -4.9)/(sqrt(4)/sqrt(n))return(pnorm(test.stat, lower.tail =FALSE) <0.05)}results <-replicate(10^4, sapply(c(5, 80, 1280), test))apply(results, 1, mean)
[1] 0.066 0.115 0.562
# Effect on not knowing sigmatest <-function(n){ data <-rnorm(n, mean =5, sd =2) test.stat <- (mean(data) -4.9)/(sd(data)/sqrt(n))return(pnorm(test.stat, lower.tail =FALSE) <0.05)}results <-replicate(10^4, sapply(c(5, 80, 1280), test))apply(results, 1, mean)
[1] 0.105 0.121 0.567
test <-function(n){ data <-rnorm(n, mean =5, sd =2) test.stat <- (mean(data) -4.8)/(sqrt(4)/sqrt(n))return(pnorm(test.stat, lower.tail =FALSE) <0.05)}results <-replicate(10^4, sapply(c(5, 80, 1280), test))apply(results, 1, mean)
[1] 0.0741 0.2250 0.9756
# Effect on not knowing sigmatest <-function(n){ data <-rnorm(n, mean =5, sd =2) test.stat <- (mean(data) -4.8)/(sd(data)/sqrt(n))return(pnorm(test.stat, lower.tail =FALSE) <0.05)}results <-replicate(10^4, sapply(c(5, 80, 1280), test))apply(results, 1, mean)
[1] 0.120 0.223 0.973
Now let us change \(\alpha=0.05\) to \(\alpha=0.01\). What will happen to the simulation results?
We look first at testing a true null \(\mu=5\) against \(\mu>5\).
Next, we look at testing a false null \(\mu=4.9\) against \(\mu>4.9\).
Finally, we look at testing a false null \(\mu=4.8\) against \(\mu>4.9\).
Then compare with the findings from \(\alpha=0.05\).
test <-function(n){ data <-rnorm(n, mean =5, sd =2) test.stat <- (mean(data) -5)/(sqrt(4)/sqrt(n))return(pnorm(test.stat, lower.tail =FALSE) <0.01)}results <-replicate(10^4, sapply(c(5, 80, 1280), test))apply(results, 1, mean)
[1] 0.0086 0.0087 0.0104
# Effect on not knowing sigmatest <-function(n){ data <-rnorm(n, mean =5, sd =2) test.stat <- (mean(data) -5)/(sd(data)/sqrt(n))return(pnorm(test.stat, lower.tail =FALSE) <0.01)}results <-replicate(10^4, sapply(c(5, 80, 1280), test))apply(results, 1, mean)
[1] 0.0405 0.0102 0.0093
test <-function(n){ data <-rnorm(n, mean =5, sd =2) test.stat <- (mean(data) -4.9)/(sqrt(4)/sqrt(n))return(pnorm(test.stat, lower.tail =FALSE) <0.01)}results <-replicate(10^4, sapply(c(5, 80, 1280), test))apply(results, 1, mean)
[1] 0.0127 0.0290 0.2907
# Effect on not knowing sigmatest <-function(n){ data <-rnorm(n, mean =5, sd =2) test.stat <- (mean(data) -4.9)/(sd(data)/sqrt(n))return(pnorm(test.stat, lower.tail =FALSE) <0.01)}results <-replicate(10^4, sapply(c(5, 80, 1280), test))apply(results, 1, mean)
[1] 0.0485 0.0323 0.2970
test <-function(n){ data <-rnorm(n, mean =5, sd =2) test.stat <- (mean(data) -4.8)/(sqrt(4)/sqrt(n))return(pnorm(test.stat, lower.tail =FALSE) <0.01)}results <-replicate(10^4, sapply(c(5, 80, 1280), test))apply(results, 1, mean)
[1] 0.0190 0.0756 0.8952
# Effect on not knowing sigmatest <-function(n){ data <-rnorm(n, mean =5, sd =2) test.stat <- (mean(data) -4.8)/(sd(data)/sqrt(n))return(pnorm(test.stat, lower.tail =FALSE) <0.01)}results <-replicate(10^4, sapply(c(5, 80, 1280), test))apply(results, 1, mean)
[1] 0.0559 0.0789 0.8935
Sample size calculations
We have wrestled a lot with the notion that sample sizes may not be large.
Even before data collection, it may be possible to plan for an appropriate sample size to achieve a particular goal.
We don’t go through all the details but a relatively simple illustration will suffice.
For example, you want to estimate a population mean. What should be the sample size so that it would be accurate up to 0.01 units with probability 0.99?
In other words, you want to find \(n\) so that \[\mathbb{P}\left(|\overline{X}_n-\mu|\leq 0.01\right)=0.99.\]
We can answer this by Chebyshev’s inequality or the central limit theorem.
To use Chebyshev’s inequality, we need to have the right form, i.e., either \[\mathbb{P}\left(|X-\mathbb{E}(X)| \geq t\right)\leq \frac{\mathsf{Var}(X)}{t^2}\]
Or \[\mathbb{P}\left(|Z|\geq k\right)\leq \frac{1}{k^2}.\] Note that the \(Z\) here is a standardized random variable, not necessarily having a standard normal distribution.
But \(Z\) here has to be \(\dfrac{\overline{X}_n-\mu}{\sigma/\sqrt{n}}\) and, unfortunately, you need to know \(\sigma\).
We could try different levels of \(\sigma\) in order to get a sense of the necessary sample sizes.
If you want to use the central limit theorem, we observe that \[\mathbb{P}\left(\bigg|\dfrac{\overline{X}_n-\mu}{\sigma/\sqrt{n}}\bigg| \leq \frac{0.01}{\sigma/\sqrt{n}}\right) \approx \mathbb{P}\left(|Z|\leq \frac{0.01}{\sigma/\sqrt{n}}\right)=0.99\] and \(Z\sim N(0,1)\).
Observe that \[\mathbb{P}\left(|Z|\leq z\right)=\mathbb{P}(-z\leq Z\leq z)\]
The value of z such that \(\mathbb{P}\left(|Z|\leq z\right) =0.99\) would be
qnorm(0.005)
[1] -2.58
So \(z\) is equal to 2.576. We now have \[\frac{0.01}{\sigma/\sqrt{n}}=2.58\]
If we have values for \(\sigma\), we can solve for \(n\).
Here the goal is to gain some accuracy in point estimation. If you have other goals like finding a sample size which will enable you to detect with high probability a difference from a status quo, then the calculations will be slightly different but will eventually use a similar style of argument.