[1] 14.6537[1] 0.5123799[1] 0.06972608Vignettes, moving forward
2024-12-02
Suppose you want to test the null that \(\mu=5\) against \(\mu>5\) for whatever legitimate reason. The idea is to design a decision rule like “Reject the null whenever \(\overline{X}_n\) exceeds a threshold” in order to achieve control of the probability of a Type I error.
The question is how to determine the threshold. The central limit theorem can be useful here once more.
Theorem 1 (Wasserman (2004) p.78, Theorem 5.10)) Suppose \(X_1, \ldots, X_n\) are IID random variables with mean \(\mathbb{E}(X_i)=\mu\) and \(\mathsf{Var}\left(X_i\right)=\sigma^2\). Then, \[Z_n=\frac{\sqrt{n}\left(\overline{X}_n-\mu\right)}{S_n}\overset{d}{\to} N(0,1)\]
Moving beyond Theorem 1 of Lecture 5d, the weak law of large numbers, and the central limit theorem would be the next steps.
So far, we focused on a setting where \(X_1, \ldots, X_n\) are IID random variables with \(\mu=\mathbb{E}\left(X_i\right)\), and \(\sigma^2=\mathsf{Var}\left(X_i\right)\).
You can extend to random vectors and then study vector of parameters or even parameters that quantify relationships between elements of a random vector.
Call:
lm(formula = total_weight ~ 1, data = mandm)
Residuals:
Min 1Q Median 3Q Max
-1.3537 -0.4037 -0.0037 0.3463 1.5463
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 14.65370 0.06973 210.2 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.5124 on 53 degrees of freedom 2.5 % 97.5 %
(Intercept) 14.51385 14.79356 1 2 3 4 5 6
14.83077 14.54286 14.84545 14.40000 14.64545 14.30000
Call:
lm(formula = total_weight ~ factor(scale), data = mandm)
Residuals:
Min 1Q Median 3Q Max
-1.00000 -0.30000 -0.03811 0.30000 1.35455
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 14.83077 0.13832 107.217 <2e-16 ***
factor(scale)2 -0.28791 0.23381 -1.231 0.2242
factor(scale)3 0.01469 0.20432 0.072 0.9430
factor(scale)4 -0.43077 0.23381 -1.842 0.0716 .
factor(scale)5 -0.18531 0.20432 -0.907 0.3689
factor(scale)6 -0.53077 0.26245 -2.022 0.0487 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.4987 on 48 degrees of freedom
Multiple R-squared: 0.1419, Adjusted R-squared: 0.05255
F-statistic: 1.588 on 5 and 48 DF, p-value: 0.1815In our course, our focus is on models like \[Y_i=\beta_0+\varepsilon_i,\ \mathbb{E}\left(\varepsilon_i\right)=0,\ \mathsf{Var}\left(\varepsilon_i\right)=\sigma^2\] where \(\beta_0\) has a very special meaning.
In ECOMETR, you will be looking into models like \[Y_i=\beta_0+\beta_1 X_i+\varepsilon_i\] with suitable assumptions about \(\varepsilon_i\) or \(\beta_0\), \(\beta_1\), and \(\beta_0+\beta_1X_i\) will also have special meanings.
The record I know is as follows: In January 2006, the website for M&M candies claimed that 20% of plain M&M candies are orange, 16% green, 14% yellow, 13% each red and brown, and 24% are blue.
We want to test whether the data we have collected is compatible with the claim above.
Let \(\theta=(\theta_{\mathsf{orange}}, \theta_{\mathsf{green}}, \theta_{\mathsf{yellow}}, \theta_{\mathsf{red}}, \theta_{\mathsf{brown}}, \theta_{\mathsf{blue}})\). \(\theta\) is a parameter representing the probability mass function of a random variable representing color.
We want to test the null that \(\theta=(0.2, 0.16, 0.14, 0.13, 0.13, 0.24)\) against the alternative that \(\theta\neq(0.2, 0.16, 0.14, 0.13, 0.13, 0.24)\).
It is easy to generate artificial data under the null.
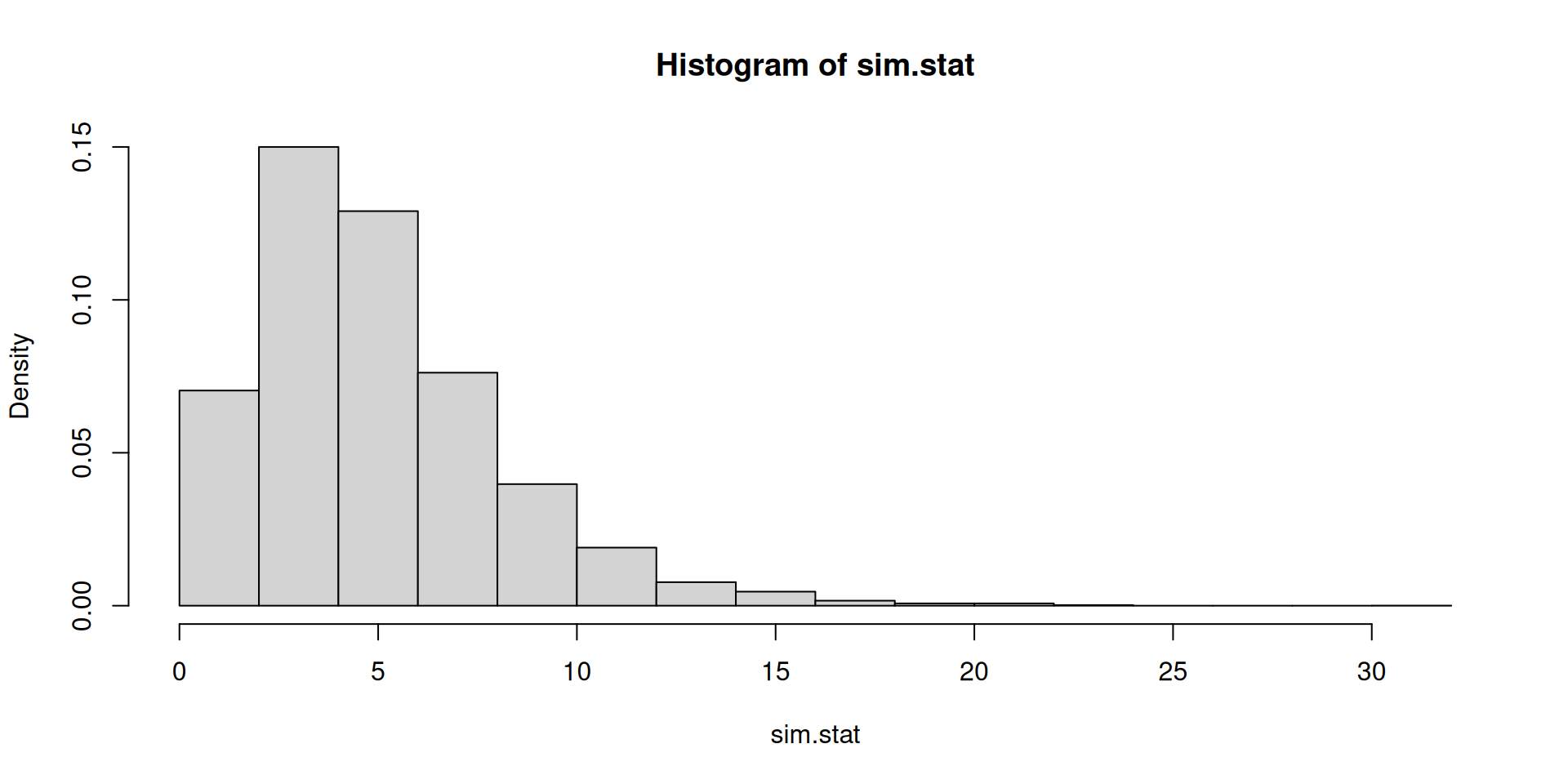
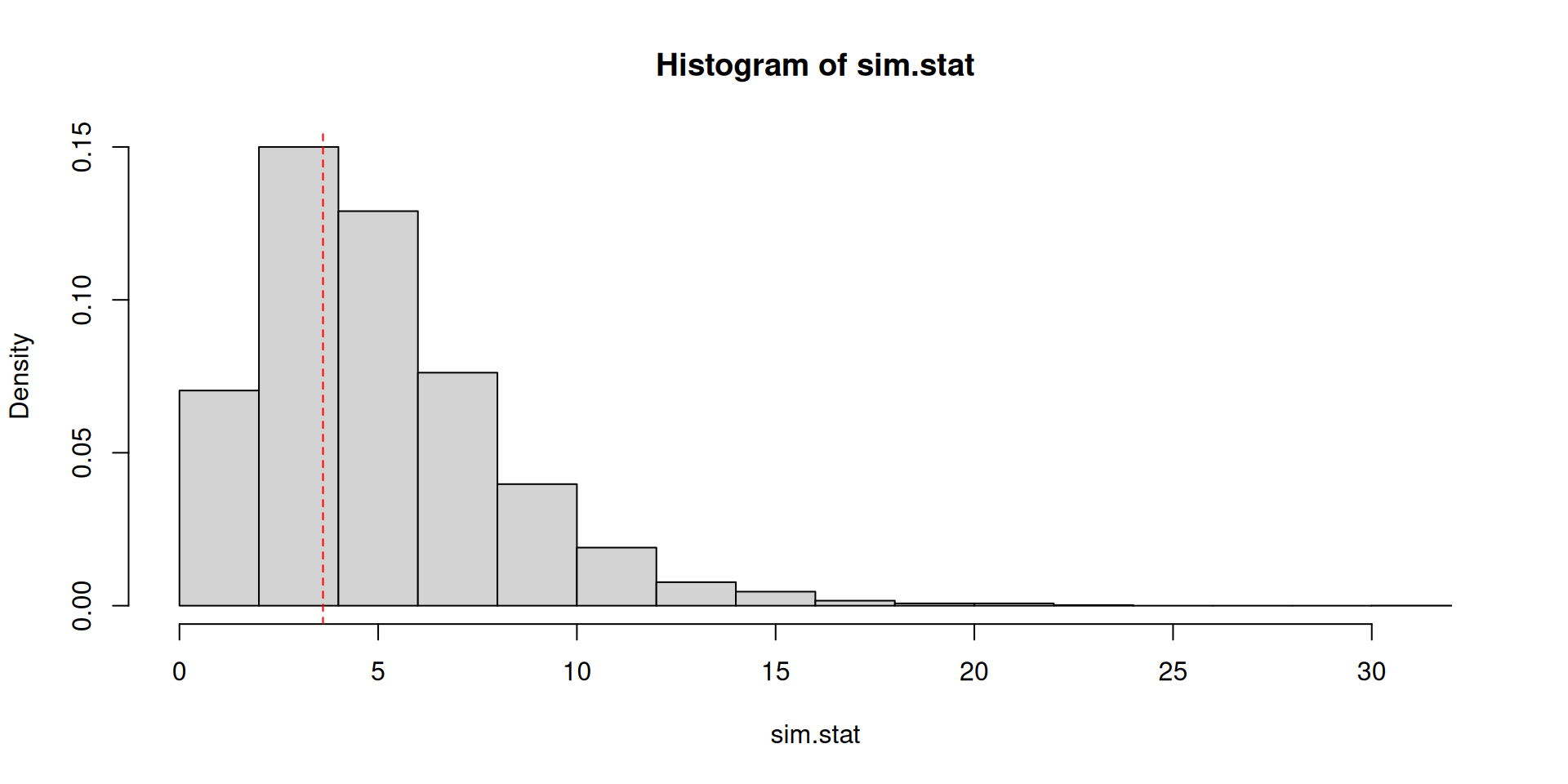
To develop a test, the idea is to think about the following test statistic: \[\sum_{\mathsf{all}\ \mathsf{categories}} \frac{\left(\mathsf{observed}\ \mathsf{counts}-\mathsf{expected}\ \mathsf{counts}\right)^2}{\mathsf{expected}\ \mathsf{counts}}\]
This is called a Pearson \(\chi^2\) statistic (refer to Wasserman Section 10.3).
observed.counts <- mandm[1, c("n_orange", "n_green", "n_yellow", "n_red", "n_brown", "n_blue")]
observed.counts n_orange n_green n_yellow n_red n_brown n_blue
1 2 3 2 3 4 2observed.counts <- mandm[1, c("n_orange", "n_green", "n_yellow", "n_red", "n_brown", "n_blue")]
observed.counts n_orange n_green n_yellow n_red n_brown n_blue
1 2 3 2 3 4 2[1] 3.20 2.56 2.24 2.08 2.08 3.84[1] 3.612237a <- replicate(10^4, sample(c(1, 2, 3, 4, 5, 6), 16, prob = c(0.2, 0.16, 0.14, 0.13, 0.13, 0.24), replace = TRUE))
calc.stat <- function(data)
{
obs_n <- 16
obs_orange <- sum(data == 1)
obs_green <- sum(data == 2)
obs_yellow <- sum(data == 3)
obs_red <- sum(data == 4)
obs_brown <- sum(data == 5)
obs_blue <- sum(data == 6)
observed.counts <- c(obs_orange, obs_green, obs_yellow, obs_red, obs_brown, obs_blue)
expected.counts <- obs_n*c(0.2, 0.16, 0.14, 0.13, 0.13, 0.24)
test <- sum((observed.counts - expected.counts)^2/expected.counts)
return(test)
}
sim.stat <- apply(a, 2, calc.stat)[1] 0.6197In practice, there are broadly three estimation approaches used in economics:
lm() command)You actually are using method of moments without even realizing it.
Try using the computer to obtain a standard error even if the theory-based standard error may be hard to obtain
Sample size \(n=50\), number of resamples \(B=200\)
Sample size \(n=100\), number of resamples \(B=200\)
[1] 5 5 3 2 5 5 5 5 5 5 5 5 5 5 2 5 5 5 5 5 5 5 3 3 5 3 3 5 5 5 5 5 3 5 5 5 5
[38] 5 3 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 3 5 5 5 2 5 5 5 5 3 5 5 3 5 5 5 5 5 5 3
[75] 5 3 5 5 3 5 5 5 3 3 5 5 5 2 5 5 5 5 5 5 5 2 5 5 5 5[1] 4.55resamples <- replicate(200, sample(data, replace = TRUE))
collect.means <- apply(resamples, 2, mean)
sd(collect.means)[1] 0.09962134[1] 0.1024695As an exercise, try repeating the code above on your own computer. What changed? What did not change?
What we have done is called the nonparametric bootstrap.
Notice that if we did not know how to derive the theoretical standard error of \(\sigma/\sqrt{n}\), we would not know what standard error to report. We also may not be able to compute confidence intervals or test hypotheses. Therefore, having a tool like the bootstrap actually helps in practice.
Natural questions to ask include:
mean(collect.means). Is there something to learn from mean of the estimates obtained from the resampled data?Other questions to ask and explore
To learn more and to see different versions of the bootstrap, feel free to explore using my notes here.
People are always excited with handling data.
The course placed emphasis on
The course reduced emphasis on
If you want more realistic datasets, I would recommend the following resource, but you may have to do some modifications to be able to make things work.